JAVA基础
1.基本数据类型 : byte short int long float double char boolean
byte char short 平级 int float long double
2.引用数据类型:数组,类,接口
3.语句 if swich do while for
判断固定个数,用if或switch
switch效率相对高
switch(值){
case 值:要执行的代码;
break;
}
break可以省略,省略就一直执行直到遇见break,break用来跳出循环,循环嵌套时,break只跳出当前所在循环continue:结束本次循环,开始下次循环 "值" 是byte char short int类型
while, for 可以互换,如需控制循环次数,用for,for循环结束后变量会在内存释放
4.函数
函数就是单独的功能体现,可以理解为一个方法
作用:1.定义功能 2.封装代码,提高复用性,一个函数可以多次使用
注意:函数中只能调用函数,不能定义函数
主函数的作用:1.保证类独立运行 2.程序的入口 3.被jvm调用
重载 :函数名一样,参数不一样
重写 :函数名一样,内容不一样
5.数组
用于储存同一类型数据的容器,编号从0开始,是封装数据的具体实体
定义方式
int a = new int[5]
int a ={0,1,2}
int a = new int[]{0,1,2}
//二分查找法。必须有前提:数组中的元素要有序。
public static int halfSeach_2(int[] arr,int key){
int min,max,mid;
max = arr.length—1;
mid = (max+min)>>1; //(max+min)/2;
while(arr[mid]!=key){
if(key>arr[mid]){
min = mid + 1;
}
else if(key<arr[mid])
max = mid — 1;
if(max<min)
return —1;
mid = (max+min)>>1;
}
return mid; }
内存java分5片内存 1.寄存器 2.本地方法区 3.方法区 4.栈 5.堆
栈 后进先出,储存局部变量,即用即释放
堆 先进先出,储存实体,每个实体都有内存首地址
6.面向对象
特点:
1.将复杂的事情简单化
2.符合现在人们的思考习惯
3.从执行者变为指挥者
面向过程:一步一步来,偏过程化,强调功能行为,先后顺序,用函数将步骤一步步实现,使用时依次调用函数。
面向对象:站在对象的角度思考问题,将功能放在不同的对象里,强调的是具备某些功能对象,最小的程序单元是类
7.成员变量和局部变量
成员变量
定义在类中,整个类有效,存在堆内存,随该对象的消失而消失
局部变量
定义在方法,参数,语句上,只在该大括号内生效,存在栈中,大括号结束释放
8.构造函数
用于给对象初始化,名字与类的名字相同,不需要定义返回值类型,没有具体返回值。所有类都需要初始化才能使用,一个类定义时如果没有定义构造函数(有参构造),会默认生成一个无参构造,如果定义了有参构造,无参构造会被覆盖。一个类可以有多个构造函数,以重载体现
什么时候使用构造函数:分析该事务,发现该事务出生时就有一些特征,这些特征要定义在构造函数里
构造代码块:给所有对象进行初始化时调用,所有对象共同调用一个构造代码块,对象每建立一次就会调用一次
Person p = new Person();
创建一个对象都在内存中做了什么事情?
1:先将硬盘上指定位置的Person.class文件加载进内存。
2:执行main方法时,在栈内存中开辟了main方法的空间(压栈—进栈),然后main方法的栈区分配了一个变量p。
3:在堆内存中开辟一个实体空间,分配了一个内存首地址值。 4:在该实体空间中进行属性的空间分配,并进行了默认初始化。 5:对空间中的属性进行显示初始化。
6:进行实体的构造代码块初始化。
7:调用该实体对应的构造函数,进行构造函数初始化。
8:将首地址赋值给p ,p变量就引用了该实体。(指向了该对象)
9.面向对象的三大特征:封装,继承,多态
封装:隐藏对象的属性和实现细节,只对外提供访问方式
优点:安全性,重用性高,方便使用
static:静态修饰符,用于修饰成员变量和成员函数
特点:
1.要共享这个对象,用static修饰
2.被static修饰的成员可以直接被类名调用
3.跟这类一起加载,意味着类产生的时候这个对象就产生了 4.存在于方法区中,随类的加载而加载,类的消失而消失
成员变量是对象的特有数据,静态变量是对象的共享数据
静态代码块:定义在类中,可以完成类的初始化,随类的加载而执行,只执行一次,如果主函数在一个类,优于主函数执行。
特点:
1.提高代码复用性
2.让类与类之间产生关系,提供多态的前提
单继承:一个类只有一个父类
多继承:一个类有多个父类。java中只支持单继承,但接口实际上支持了多继承
子类调用父类属性值用super关键字,this和super都要放在函数第一行,二者不能共存,子类构造函数运行时会先运行父类构造函数,因为子类构造函数第一行会有隐藏的super语句,子类继承了父类的属性,就要先将父类的对象初始化,如果父类没有无参构造,子类的构造函数中必须用super访问父类中的构造函数
final:用来修饰类,方法,变量
被修饰的类,不能被继承;被修饰的方法,不能被覆盖;被修饰的变量,只能赋值一次
抽象类 abstract
特点
1.只定义在抽象类中,必须用关键词修饰
2.只注重方法声明,不注重方法实现
3.不能被实例化,必须通过子类继承该抽象类中的所有抽象方法,该子类才能被实例化
4.抽象类中是有构造函数的,用来给子类初始化
5.抽象类中是可以定义非抽象方法的
6.abstract不能和final,private,static共存.
接口 interface
接口里有抽象方法,也不能实例化,类似抽象类,类与类之间是继承extends,接口与接口之间是实现 implements接口可以被多实现,是多继承改良的后果,避免了单继承的局限性
接口与接口之间可以多继承
接口是对外提供的规则,功能的扩展,降低了耦合性
抽象类跟接口都是不断向上抽取的结果
区别:
1.抽象类只能被继承,单继承,接口是被实现,可以被多实现
2.抽象类中可以定义抽象和非抽象方法,子类直接继承使用,接口中的抽象方法需要子类实现
3.抽象类的成员修饰符可以自定义,接口都是Public
多态
体现:父类引用或者接口引用指向自己的子类 Animal a = new Cat();
好处: 提高程序扩展性
弊端:父类引用指向子类,只能访问父类中的方法,不能访问子类中的方法,前期不能用后期的功能,访问的局限性
前提:要有关系,继承,实现,通常会有覆盖操作
理解:多态里,自始至终都是子类对象在做着类型变化。父与子,父是高,子是低,子类对象可以调用父类对象里的方法,但父类对象不能调用子类中的方法,除非父类对象转成子类,高转低需要强转,因为子类里面有很多新东西父类是不一定有的,低转高不需要强转,因为父类里有的东西子类一定有
如果想用子类对象的特有方法,如何判断对象是哪个具体的子类类型呢?可以通过一个关键字 instanceof ;
//判断对象是否实现了指定的接口或继承了指定的类格式:<对象 instanceof 类型> ,判断一个对象是否所属于指定的类型。Student instanceof Person = true;//st
异常
Throwable:可抛出的
Error:错误,通常是jvm产生的
Exception:异常,可以有针对性的处理
这个体系中的所有类和对象都具备一个独有的特点,就是可抛性。
可抛性的体现:就是这个体系中的类和对象都可以被throws和throw两个关键字所操作
throw用于抛出异常对象,后面跟异常对象,用在函数内
throws用于抛出异常类,后面跟类名,用在函数上
异常分为编译时被检查的异常跟运行时异常,Exception及其子类都是编译时异常Excepiton特殊子类RuntimeException及它的子类是运行时异常
区别:编译时异常在函数内被抛出,函数必须声明,否则编译失败,声明原因时需要调用者对该异常进行处理,运行时异常在函数内被抛出不需要声明
什么时候try什么时候throws
功能内部异常,如果内部可以处理,用try,如果处理不了,必须声明出来让调用者处理。
常见异常
脚标越界异常(IndexOutOfBoundsException)包括数组、字符串;
空指针异常(NullPointerException)
类型转换异常:ClassCastException
没有这个元素异常:NoSuchElementException
不支持操作异常:UnsupportedOperationException
常见软件包
java.lang 语言
java.awt图形界面开发对象
javax.swing提供所有的windows桌面应用程序包括的控件
java 网络编程对象
java.io 操作设备上数据的对象
java.util工具包,时间对象,集合框架
java.applet客户端java小程序多线程
进程:正在进行中的程序。进程是一个应用程序运行时的内存分配空间
线程:进程中的一个程序执行控制单元。一个进程至少有一个线程在运行,如果进程中有多个线程,这就是多线程程序,每个线程在栈区都有各自的执行空间,方法,变量。jvm在启动时,首先有一个主线程负责程序的执行,调用main函数
随机性的原理:因为cpu高速切换,哪个线程获得了cpu执行权,那个线程就执行。
返回当前线程的名称:Thread.currentThread().getName()
线程的名称是由:Thread—编号定义的。编号从0开始。线程要运行的代码都统一存放在了run方法中。线程要运行必须通过start方法开启,启动了线程,让jvm调用run方法
创建线程
1.继承Thread类,子类复写run方法。定义一个类继承Thread类,复写run方法,将要运行的代码写进run方法里,通过创建该子类对象创建线程对象,调用start方法开启线程,执行run方法
2.实现Runnable接口,定义一个类实现Runnable接口,覆盖run方法,通过Thread类创建线程对象,将该实现类的子类对象作为实参传给Thread类的构造函数,调用start方法开启线程,运行run方法
线程的状态
被创建
start()
运行
具备执行资格,具备执行权
冻结
线程释放了执行权
临时阻塞
有执行资格,但没执行权
消亡
stop()
为什么会有Runnable接口
单继承的局限性,如果一个类已经有了父类,那就不能继承Thread类,实现该接口可以避免单继承的局限性,它将线程要执行的任务封装成一个对象
run方法和start方法的区别
程序调用start方法时一个新线程会被创建,并且在run方法中的代码会在新线程上运行,直接调用run方法不会创建新线程,run内部的代码会在当前线程上运行。如果要运行需要消耗大量时间的任务,最好使用start方法,否则调用run方法时主线程会被卡住。一旦一个线程被启动,不能重复调用该thread对象的start方法,调用已启动线程的start方法会报异常,但run方法可以重复调用。
多线程的安全问题
1.多个线程操作共享数据
2.多条语句对共享数据进行运算这些语句在某一时刻被一个线程执行时,还未执行完就被其他线程执行了
解决原理:执行完前不让其他线程执行
解决方法:同步代码块
同步
优点:解决线程安全问题
缺点:降低性能
前提
1.有两个或以上的线程
2.多个线程必须保证使用同一个锁
同步函数和同步代码块
同步代码块使用的锁可以是任意对象,同步函数使用的锁是this,一个类中只能有一个同步时,可以使用同步函数,如果有多个同步,必须使用同步代码块。同步代码块更灵活
常见的javaAPI
String字符串一旦被初始化就不能改变
常见的String字符串方法
length();获取长度
char charAt(int index)获取指定位置的字符
int indexOf(int ch)获取指定字符的位置
String substring截取子符串
equals判断是否相同
String[] split分割字符串
String replace(old,new)字符串内容替换
compareTo();参数字符串=该字符串,返回0,小于,返回<0,大于返>0
StringBuffer和StringBuilder
可以对字符串的内容进行修改,是一个可变长度的容器,可以储存任意类型的数据,最后要变成字符串
固定方法
append追加数据到尾部
insert插入数据
delete删除
replace替换
indexOf查找
reverse反转
二者的区别
Buffer线程安全,效率低,Builder不安全,效率高,单线程用Builder,多线程用Buffer
包装类
byte Byte
short Shor
int Integer
long Long
float Float
double Double
char Character
Boolean Boolean
除了Character,都有 XXX parseXXX方法
集合框架特点
1.用于储存对象
2.可变长度
和数组的区别
1.数组长度固定,集合可变
2.数组可以储存基本数据类型和引用数据类型(接口,类,数组),集合只能储存引用数据型
3.数组必须保证储存的都是同一数据类型,集合不用
数据结构:就是容器中存储数据的方式。
类型有
线性表(ArryaList)链表(LinkedList)队列(Queue)图(Map)树(Tree)
Collection接口
List:有序,存入和取出顺序一致,元素有索引,可以重复
Set:无序,不可重复
Iterator接口迭代器,是一个接口,用于取集合中的元素
List接口是Collection接口的子接口,最大特点是List的特有方法都有索引有序,元素都有索引,可以重复
1.ArrayList:线程不同步,查找快,增删慢,底层数据结构是数组2.LinkedList:线程不同步,增删快,查找慢,底层数据结构是双链表3.Vector:线程同步,查找增删都慢,底层数据结构是数组
常用方法
add插入一个元素
addAll插入一堆元素
remove删除
indexOf获取指定元素第一次出现的索引为
Object set修改
listIterator获取所有元素,list特有的迭代器List集合支持对元素的增删改查
Set接口
Set接口取出方式只有使用迭代器
1.HashSet:线程不同步,无序,高效,保证唯一性通过元素的HashCode方法结合equals实现。元素的HashCode相同,才使用equals,不同则不用使用
2.LinkedHashSet:有序,是HashSet的子类
3.TreeSet:不同步,底层是二叉树,对Set集合中的元素进行指定顺序的排序
哈希表的原理
1.对对象元素中的关键字进行哈希算法运算,得到哈希值
2.哈希值是这个元素的位置
3.如果元素的哈希值相同,再判断这两个元素是否相同,如果相同,不用重复储存,如果不,向后延伸储存
4.存储哈希值的结构叫哈希表
对于ArrayList,判断元素是否存在或者删除元素,依据equals方法
对于HashSet,依据HashCode和equals
TreeSet
用于对Set集合进行元素的指定顺序排序,排序需要依据元素自身具备的比较性如果元素不具备比较性,运行时会发生ClassCastException异常
所以需要元素实现Comparable接口,强制让元素具备比较性,复写CompareTo方法依据返回值,确定元素的位置,如果返回0,证明该元素存在,不储存,这就是保证唯一性方法判断是,需要分主要条件和次要条件,主要条件相同,再判断次要条件,按照次要条件排序两种排序方式
Comparable Comparetor
1.让元素自身具备比较性,需要元素对象实现Comparable 接口,覆盖compareTo方法
2.让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,覆盖compare法,将该类对象作为实参传递给TreeSet集合构造函数,第二种方法较为灵活
Map集合
HashTable:线程同步,不可存null,底层哈希表
HashMap:线程不同步,可以存null底层哈希表
TreeMap:可以对map集合中的键进行指定顺序的排序,底层二叉树
Map集合存储和Collection有很大不同
Collection一次存一个元素,Map存一对
Collection是单例结合,Map是双列Map存的是键值对,要保证键的唯一性
Collection 和 Collections的区别:
Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。
Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历。
get请求和post请求的区别
get请求的数据多附加在url之后以?分割URL和传输数据,多个参数用&连接。URL的编码格式时ASCII格式,不是uniclde,所有的非ASCII字符都要编码后再传输
post请求会把请求的数据放置在HTTP请求包的包体中,上面的item=bandsaw就是实际传输的数据
总结就是,get请求的数据会暴露在地址栏中,且传输数据会收到url长度的限制,post不会暴露且不受限制,所以post请求的安全性要比get请求高
后端接受前端参数的三种注解方式
1.@RequestParam注解
作用:将指定的请求参数赋值给方法中的形参
接受形式:get传参请求
属性:value:绑定请求参数名,默认绑定同名形参;required:是否必须,默认true,表示请求中一定要有相应参数,否则报错;defaultValue默认值,表示如果请求中没有接收到该值的默认值
2.@PathVariable注解
1. 作用:接受请求路径中占位符的值
2. 接受形式:get路径请求
3. 属性:value:String形式,绑定请求的参数,默认绑定同名形参
3.@RequestBody注解
1. 作用:接受前端传递的json字符串
2. 接受形式:post请求
增强for循环
for(元素类型 变量名 : 集合/数组){
}
枚举类enum
针对对象的某个属性的值不能任意,必须是固定一组数值中的某一个
常用API
Math数学运算工具类
Date日期类月份0-11日期转字符串
formatCalendar日历类
IO流 用于处理设备上的数据分类
1.输入流和输出流(读和写)
2.字节流和字符流
字节流:InputStream OutputStream
字符流:Reader Writer
File类:将文件系统中的文件和文件夹封装成了对象。提供了更多的属性和行为可以对这些件和文件夹进行操作。这些是流对象办不到的,因为流只操作数据。
File类常见方法:
1:创建。
boolean createNewFile():在指定目录下创建文件,如果该文件已存在,则不创建。而对作文件的输出流而言,输出流对象已建立,就会创建文件,如果文件已存在,会覆盖。除续写。
boolean mkdir():创建此抽象路径名指定的目录。
boolean mkdirs():创建多级目录。
2:删除。
boolean delete():删除此抽象路径名表示的文件或目录。
void deleteOnExit():在虚拟机退出时删除。注意:在删除文件夹时,必须保证这个文件夹中没有任何内容,才可以将该文件夹用delete删除。window的删除动作,是从里往外删。注意:java删除文件不走回收站。要慎用。
3:获取.
long length():获取文件大小。
String getName():返回由此抽象路径名表示的文件或目录的名称。String getPath():将此抽象路径名转换为一个路径名字符串。
String getAbsolutePath():返回此抽象路径名的绝对路径名字符串。String getParent():返回此抽象路径名父目录的抽象路径名,如果此路径名没有指定父目,则返回 null。
long lastModified():返回此抽象路径名表示的文件最后一次被修改的时间。
File.pathSeparator:返回当前系统默认的路径分隔符,windows默认为 “;”。
File.Separator:返回当前系统默认的目录分隔符,windows默认为 “\”。4:判断:
boolean exists():判断文件或者文件夹是否存在。
boolean isDirectory():测试此抽象路径名表示的文件是否是一个目录。boolean isFile():测试此抽象路径名表示的文件是否是一个标准文件。boolean isHidden():测试此抽象路径名指定的文件是否是一个隐藏文件。
boolean isAbsolute():测试此抽象路径名是否为绝对路径名。
5:重命名。
boolean renameTo(File dest):可以实现移动的效果。剪切+重命名。String[] list():列出指定目录下的当前的文件和文件夹的名称。包含隐藏文件。如果调用list方法的File 对象中封装的是一个文件,那么list方法返回数组为null。如果封装对象不存在也会返回null。只有封装的对象存在并且是文件夹时,这个方法才有效。
反射
动态加载一个指定的类,并获得该类中的所有内容,反射技术可以对一个类进行解剖
好处:大大增强了程序的扩展性
基本步骤:
1.获得Class对象,就是获取到指定的名称的字节码文件对象
2.实例化对象,获得类的属性,方法和构造函数
3.访问属性,调用方法,调用构造函数创建对象
如何获取Class对象
1.通过getClasss,但必须要创建该类对象才可以调用
2.静态的属性class,但必须先声明该类
前两种都不利于程序的扩展,因为都需要在程序使用具体的类完成
3.使用Class类中的forName方法指定什么类名,就获取什么类的字节码文件对象,只需要将类名的字符串传入即可
// 1. 根据给定的类名来获得 用于类加载
String classname='xxxxxxxx';
Class clazz = Class.forName(classname);
// 2. 如果拿到了对象,不知道是什么类型 用于获得对象的类型Object obj = new Person();
Class clazz1 = obj.getClass();// 获得对象具体的类型
// 3. 如果是明确地获得某个类的Class对象 主要用于传参
Class clazz2 = Person.class;
反射的用法:
1)、需要获得java类的各个组成部分,首先需要获得类的Class对象,获得Class对象的三方式:
Class.forName(classname) 用于做类加载
obj.getClass() 用于获得对象的类型
类名.class 用于获得指定的类型,传参用
2)、反射类的成员方法:
Class clazz = Person.class;
Method method = clazz.getMethod(methodName, new Clas[{paramClazz1,paramClazz2});
method.invoke();
3)、反射类的构造函数:
Constructor con = clazz.getConstructor(new Clas[{paramClazz1,paramClazz2,...})
con.newInstance(params...)
4)、反射类的属性:
Field field = clazz.getField(fieldName);
field.setAccessible(true);
field.setObject(value);
获取了字节码文件对象后,最终都需要创建指定类的对象:
创建对象的两种方式(其实就是对象在进行实例化时的初始化方式):1,调用空参数的构造函数:使用了Class类中的newInstance()方法。2,调用带参数的构造函数:先要获取指定参数列表的构造函数对象,然后通过该构造函数对象的newInstance(实际参数) 进行对象的初始化。 综上所述,第二种方式,必须要先明确具体的构造函数的参数类型,不便于扩展。所以一情况下,被反射的类,内部通常都会提供一个公有的空参数的构造函数
B/S 浏览器/服务器程序
C/S 客户端/服务
MySql
创建表
create table '表名' (
‘xx’列类型 [属性][索引][注释]
)
数值类型
tinyint 非常小的数据
smallint 较小
mediumint中等大小
int 标准中等整数
bigint 较大整数
float 单精度浮点数
double 双精度浮点数
decimal 字符串形式浮点数
字符串类型
char[(M)] 固定长字符串,检索快,费空间
varchar[(M)] 可变字符串
tinytext 微型文本串
text 文本串
日期和时间类
DATE YYYY-MM-DD,日期格式
TIME Hh:mm:ss,时间格式
DATETIME YYYY-MM-DD hh:mm:ss
TIMESTAMP YYYYMMDDhhmmss 格式表示的时间戳
YEAR YYYY格式的年份
数据表类型
MyISAM,InnoDB
名称 MyISAM InnoDB
事务 不支持 支持
数据行锁定 不支持 支持
外键 不支持 支持
全文索引 支持 不支持
表空间大小 小 大,约2倍
适用场合 节约空间及响应速度 安全性,事务处理,多用户操作
修改数据库
修改表名 ALTER TABLE 旧 RENAME AS 新
添加字段 ALTER TABLE 表名 ADD字段名 列属性[属性]
修改字段 ALTER TABLE 表名 MODIFY 字段名 列类型[属性]
ALTER TABLE 表名 CHANGE 旧 新 列属性[属性]
删除字段 ALTER TABLE 表名 DROP 字段名
删除表 DROP TABLE 表名
如果删除不存在的表会报错
外键
将一个表的值放在第二个表中表示关联,这个值是第一个表的主键,第二个表保存这些值的属性称为外键 foreign key
作用 保持数据一致性,完整性,主要目的是控制储存在外键表中的数据,约束,使两张表形成关联,外键只能引用外表中列的值或空值
删除具有主外键关系的表时,先删子再删主
添加 INSERT
INSERT INTO 表名[(字段1,字段2,字段3)] VALUES('值1','值2','值3')
更新 UPDATE
UPDATE 表名 SET column_name= value [,column_name2=value2,...] [WHEREcondition];
删除 DELETE
DELETE FROM 表名 [WHERE condition];
TRUNCATE
清空表数据,结构索引约束不变,比DELETE速度快,但不删除表结构,会重置自增计数器,对事物没有影响
TRUNCATE [TABLE] 表名;
SELECT
SELECT * FROM TABLE
inner/left/right join TABLE2
WHERE 条件
GROUP BY 按照字段分组
HAVING 过滤分组的记录需要满足的次要条件
ORDER BY 排序
LIMIT 分页
DISTINCT 去掉重复结果
SELECT DISTINCT ID FROM TABLE;
模糊查询
IS NULL a IS NULL, a是NULL,为真
IS NOT NULL a IS NOT NULL,a不是NULL,为真
BETWEEN a BETWEEN b AND c,a在b和c之间
LIKE a LIKE b,模糊查询,a匹配b
LIKE '佐%' 查询佐
LIKE '佐_' 查询佐后面有一个字的
LIKE '佐__' 查询佐后面有两个字的
LIKE '%佐%' ,查询名字里有佐字的
IN a IN(b,c,d),a等于bcd中的某一个
连接查询
INNER JOIN 内连接,查交集,表中有至少一个匹配,返回行
LEFT JOIN 左连接,有匹配返回匹配,无匹配返回左表所有行,右表用NULL填充
RIGHT JOIN 右链接,与左连接相反
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
排序和分页
ORDER BY 排序
默认按照ASC升序对记录排序,如果想降序使用DESC关键字
ORDER BY 属性名
DESC
LIMIT分页
LIMITE [offset,x]
每页显示五条数据
LIMIT 0,5
前面的是第几页开始,后面的是大小规格
子查询
在一个查询里嵌套另一个查询,使用连接查询可以达到相同效果
-- 方法一:使用连接查询
SELECT studentno,r.subjectno,StudentResult
FROM result r
INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE subjectname = '数据库结构-1'
ORDER BY studentresult DESC;
-- 方法二:使用子查询(执行顺序:由里及外)
SELECT studentno,subjectno,StudentResult
FROM result
WHERE subjectno=(
SELECT subjectno FROM `subject`
WHERE
subjectname = '数据库结构-1'
) ORDER BY studentresult DESC;
MYSQL 函数
数据函数
SELECT ABS 绝对值
SELECT CEILING 向上取整
SELECT FLOOR 向下取整
SELECT RAND 返回随机数
SELECT SIGN 负数返回-1.正数返回1,0返回0
字符串函数
SELECT CHAR_LENGTH('xxxxxxxxxx') 返回引号里字符串的字数
SELECT CONCAT('A','B','C') 将ABC合并起来
SELECT INSERT('abcd',1,2,'ef') 替换字符串,从规定的位置(1)替换规定的长度 (2)
SELECT LOWER('shuilaiqi')小写
SELECT UPPER ('shuilaiqi') 大写
SELECT LEFT('XXXXXXXXXX',5) 从左边截取
SELECT RIGHT('XXXXXXXXXX',5) 从右边截取
SELECT REPLATE('ABCDEFG','CD','ZZ') 替换
SELECT SUBSTR('ABCDEFG',2,3)截取,从开始截取3个
SELECT REVERSE('adcdefg') 反转
日期和时间函数
SELECT CURRENT_DATE(); /*获取当前日期*/
SELECT CURDATE(); /*获取当前日期*/
SELECT NOW(); /*获取当前日期和时间*/
SELECT LOCALTIME(); /*获取当前日期和时间*/
SELECT SYSDATE(); /*获取当前日期和时间*/
-- 获取年月日,时分秒
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT HOUR(NOW());
SELECT MINUTE(NOW());
SELECT SECOND(NOW());
聚合函数
count(1/*/字段)
count(1)与count(*)得到的结果一致,包含null值。
count(字段)不计算null值
count(null)结果恒为0
SUM() 返回数字字段或表达式列统计,返回一列的和
AVG() 平均值
MAX 返回最大值
MIN返回最小值
SELECT SUM(StudentResult) AS 总和 FROM result;
SELECT AVG(StudentResult) AS 平均分 FROM result;
SELECT MAX(StudentResult) AS 最高分 FROM result;
SELECT MIN(StudentResult) AS 最低分 FROM result;
MD5加密
update 表名 set 列名 = md59(列名);
INSERT INTO testmd5 VALUES(4,'kuangshen3',md5('123456'));
事务
ACID原则
A 原子性
事务中所有操作要么都完成,要么都不完成,不能停滞在中间某个环节,出现错误则回滚到最初,就像该事务从未执行
C 一致性
事务可以封装改变状态,必须保证始终与系统处于一致,主要特征是保护性和一致性,如果五个账户各有100块,无论这五个账户怎么交易,总金额还是500块
I 隔离性
隔离状态执行事务,两个事务在相同时间执行相同的功能,事务的隔离性将保证每个事务在系统中认为只有一个在使用系统,防止事务操作间混淆
D 持久性
事务完成后,该事务对数据库的更改便持久保存在数据库中,不会被回滚
基本语法
改变自动提交模式,MySQL默认自动提交,使用事务要关闭自动提交
SET autocommit =0; 关闭
SET autocommit =1; 开启
START TRANSACTION 开始一个事务,标记事务起始点
COMMIT 提交事务给数据库
ROLLBACK 回滚事务
SET autocommit =1; 开启自动提交保存点
SAVEPOINT xxxx 设置一个叫xxxx的保存点
ROLLBACK TO SAVEPOINT xxxx 回滚到保存点 RELEASE SAVEPOINT xxxx 删除保存点
CREATE DATABASE `shop`CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `shop`;
CREATE TABLE `account` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(32) NOT NULL,
`cash` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO account (`name`,`cash`)
VALUES('A',2000.00),('B',10000.00)
-- 转账实现
SET autocommit = 0; -- 关闭自动提交
START TRANSACTION; -- 开始一个事务,标记事务的起始点
UPDATE account SET cash=cash-500 WHERE `name`='A';
UPDATE account SET cash=cash+500 WHERE `name`='B';
COMMIT; -- 提交事务
# rollback;
SET autocommit = 1; -- 恢复自动提交
隔离性问题
脏读:一个事务读取并修改了数据,未提交时另一个事务也访问了
丢失修改:一个事务读取数据时,修改了这个数据,另一个事务读取这个数据时也修改了,此时A对数据的修改结果就丢失了
不可重复读:一个事务读取数据时,另一个事务访问并修改了这个数据,第一个事务再次读取这个事务时发现第一次读取和第二次读取的值不一样
幻读:一个事务读取数据时,另一个事务插入了一些输入,导致前一个事务读取数据时凭空出现了一些数据
不可重复读和幻读的区别在于,不可重复读注重值被修改,幻读注重值的添加或删除
默认隔离级别
读取未提交
最低隔离级别,允许读取未提交的数据变更,可能导致脏幻不可重复读
读取已提交
允许读取已提交的数据变更,可能导致幻或不可重复读
可重复读
对同一字段多次读取结果都一样,可能导致幻读
可串行化
最高级别,所有事务一次逐个执行,完全服从ACID的隔离级别
索引
作用
1.提高查询速度
2.确保数据唯一性
3.加速表与表之间的链接,实现表之间参照完整性
4.使用分组和排序子句检索时,显著减少分组和排序的时间
5.全文检索字段进行搜索优化
分类
Primary Key 主键索引
Unique 唯一索引
Index 常规索引
FullText 全文索引
主键索引
特点
最常见的索引类型
确保数据记录的唯一性
确定特定数据记录在数据库中的位置
唯一索引
作用 避免同一个表中某数据列中的值重复
与主键索引的区别 主键索引只能有一个,唯一索引可能有多个
CREATE TABLE `Grade`(
`GradeID` INT(11) AUTO_INCREMENT PRIMARYKEY,
`GradeName` VARCHAR(32) NOT NULL UNIQUE
-- 或 UNIQUE KEY `GradeID` (`GradeID`) )
常规索引
作用 快速定位特定数据
注意
index和key关键字都可以设置常规索引
应该加在查找条件的字段
不宜添加太多,影响数据增删改操作
ALTER TABLE '表名' ADD INDEX '索引名' ('列名1','列名2');
全文索引
作用 快速定位特定数据
注意
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引; MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引
只能用于CHAR,VARCHAR,TEXT类型的列
适合大型数据集
索引准则
1.不是越多越好
2.不要对经常变动的数据加索引
3.小数据表不要加索引
4.索引一般加在查找条件字段
三大范式
第一范式
确保每列的原子性,即每列都不可再分
第二范式
首先满足第一范式,其实要求每个表只描述一件事
第三范式
首先满足一二范式,除了主键以外其他列都不传递依赖于主键列
连接池
数据库连接池负责分配,管理和释放数据库链接,它允许应用程序重复使用一个现有的数据库链接,而不是重新建立一个。
数据库连接池在初始化时将创建一定数量的数据库连接放在连接池中,数量由最小数据库链接数来设定,无论是否被使用吗,都将一直保证至少有这么多连接数量。连接池的最大数据库连接数限定了这个连接池能占有的最大链接数,当应用程序向连接池请求的链接数超过最大数,会被加入到等待队列里。
最小连接数:时连接池一直保持的数据库链接,如果应用程序对数据库连接的使用量不大,将会有大量数据库连接资源被浪费
最大连接数:连接池能申请的最大链接数,如果数据库链接请求超过次数,后面的数据库链接请求将被加入到等待队列,影响后续操作
开源数据库连接池,通常把DataSource的实现,称之为数据源,数据源中都包含了数据库连接池的实现
DBCP,C3P0,在使用了数据库连接池后,项目实际开发就不需要编写连接数据库的代码,直接从数据源中获得数据库的链接
DBCP数据源,使用需要添加Commons-dbcp.jar 连接池的实现 Commons-pool.jar依赖 C3P0 使用较多,DBCP没有自动回收空闲连接的功能C3P0有
SQL优化
1.查询语句中减少select *
2.尽量减少子查询,改用连接查询
3.减少in 或 not in,使用 exist,not exist
4.尽量避免where子句中使用!=,会将引擎放弃使用索引而进行全表扫描
5.尽量避免where子句中对字段进行null判断
MySQL中的锁
表级锁:开销小,加锁快,不会死锁,发生锁冲突的概率最高,并发度最低
行级锁:开销大,加锁慢,会出现死锁,发生锁冲突的概率最低,并发度最高
页面锁:开销和加锁时间趋于表行之间,会出现死锁,并发度一般
char和varchar
二者在存储和检索方面有所不同
char长度固定为创建表声明的长度,1-255,当char被储存时,会被用空格填充到特定长度检索char需删除尾随空格
MySQL优化顺序
1.sql语句及索引的优化
2.数据库表结构
3.系统配置
4.硬件
乐观锁
一个用户读取数据时,别人不会写自己所读的数据,悲观锁时觉得对方会读自己所读的数据,所以先对要读取的数据加锁
MyBatis
CRUD操作
namespace
配置文件中的namespace中的名称为对应Mapper接口或Dao接口的完整报名,必须一致
Select
Select是mybatis最常用标签之一
id
1. 命名空间唯一的标识符
2. 接口中的方法名与映射文件中的SQL语句ID一一对应
parameterType
1. 传入SQL语句的参数类型
resultType
<select id=”selectById” resultType=”com.zyq.wife”>
select * from user where id= #{id}
insert
标签与select差不多
<insert id=“addUser” parameterType=”com.xxx”>
insert into user (id,name) values (#{id},#{name})
</insert>
update
标签跟select差不多
<update id=”updateUser” parameterType=”com.xxx”>
update user set name=#{name} from user where id =#{id}
</update>
delete
<delete id=”updateUser” parameterType=”com.xxx”>
delete from user where id=#{id}
</delete> 对象工厂
Mybatis每次创建结果对象的实例时,都会使用对象工厂实例来完成。
生命周期和作用域
开始————SqlSessionFactoryBuilder(通过xml文件或配置文件生成SqlSessionFactory)————SqlSessionFactory————SqlSession
————SQL Mapper————结束
SqlSessionFactoryBuilder的作用在于创建SqlSessionFactory,创建成功就是去作用,所以只存在创建SqlSessionFactory的方法中,最佳作用域是方法作用域
SqlSessionFactory可以被认为是一个数据库连接池,作用是创建Sqlssioin接口对象,生命周期存在于整个MyBatis应用中,一旦创建,就要长期保存,直至不再使用Mybatis应用,它占据数据库连接资源,创建过多不利于对数据库资源控制,所以应该作为一个单例,在应用中被共享,所以最佳作用域是应用作用域
SqlSession相当于一个数据库连接,用户可以在一个事务里执行多条SQL,通过它的commit,rollback提交或回滚,它应该存活在一个业务请求中,处理完整个请求后,应该关闭该连接,归还给SqlSessionFactory,最佳作用域是请求或方法作用域
ResultMap
当实体类设置的属性值与数据库对不上时,会出现查询出空值的问题
例如,在一个实体类中,设置了name,和password属性,但在数据库中,列名是name和pwd,password和pwd并不能对上,所以查询不到
解决方法
1. 起别名
select name,pwd as password from user where …..
2. 使用结果集映射 ResultMap
<resultMap id =”UserMap” type=”user”>
<result column=“name” property = “name”/>
<result column=“pwd” property = “password”/>
</resultMap>
<select id=”selectById” resultMap=”UserMap” >
……….
</select> 使用注解开发
关于接口的理解
接口从更深层次的理解,应该是定义(规范,约束)与实现(名实分离)的分离
接口的本身反映了系统设计人员对系统的抽象理解
接口应有两类,第一类是对一个个体的抽象,可对应为一个抽象体
第二类是对一个个体某一方面的抽象,即形成一个抽象面
一个个体有可能有多个抽象面,抽象体与抽象面是有区别的
面向对象指考虑问题时,以对象为单位,考虑它的属性及方法
面向过程指考虑问题时,以一个具体的流程为单位考虑它的实现
接口设计与非接口设计是针对复用技术而言的,与面向过程(对象)不是一个问题,更多的体现是对系统整体的架构
具体注解不在这写了,很简单
关于@Param
该注解用于给方法参数起个名字,使用原则如下
1. 在方法只接受一个参数的情况下,可以不使用
2. 在方法接受多个参数的情况下,建议一定使用
3. 如果参数是JavaBean,不能使用
4. 只有在参数只有一个,且是JavaBean时,一定不能使用该注解
#与$的区别
#相当于给前端传入的数据加上‘’符号,可以有效防止SQL注入,#{}会被解析成一个参数占位符,$相当于直接把传入的数据接上去
例如前端传了一个1
where id= #{id} 等效于 where id =’1’
where id=${id} 等效于 where id=1
多对一和一对多的处理
多对一
多个学生对应一个老师,对于学生,这就是多对一
按查询嵌套处理
需求:获得所有学生及其对应老师的信息
1. 获取所有学生的信息
2. 根据学生信息中关联的老师的ID,获得该老师的信息
如何完成
1. 做一个结果集映射StudentTeacher
2. 映射的类型为Student
3. 学生中老师的属性是teacher,关联tid
<select id =”getStudents” resultMap=”StudentTeacher”>
select * from student
</select>
<resultMap id=”StudentTeahcer” type=”Student”>
<!--association关联属性 property属性名 javaType属性类
</resultMap>
<select id=”getTeacher” resultType=”teacher”>
select * from teacher where id =#{id}
</select>
按结果嵌套处理
<select id=”getStudents2” resultMap=”StudentTeacher2”>
select s.id sid,s.name sname,t.name tname from student s,
teacher t
where s.tid = t.id
</select>
<resultMap id=”StudentTeacher2” type=”Student”>
<id property=”id” column=”sid” />
<result property=”name” column=”sname”/>
<association property=”teacher” javaType=”Teacher”>
<result property=”name” column=”tname”/>
</association>
</resultMap>按照查询进行嵌套处理类似SQL中的子查询
按照结果进行嵌套处理类似SQL中的关联查询
一对多的处理
一个老师有多个学生,对于老师就是一对多的现象
思路
1. 从学生表和老师表中查出学生的id,姓名,老师的姓名
2. 从查询出来的结果做映射集
3. 集合用collection,JavaType和ofType都是用来指定对象类型的,JavaType用来指定pojo中属性的类型,ofType用来指定映射到List集合属性中的pojo类型
按照查询嵌套处理
<select id =”getTeacher2” resultMap=”TeacherStudent2”>
select * from teacher where id =#{id}
</select>
<resultMap id=”TeacherStudent2” type=”Teacher”>
这里的column是一对多的外键
<collection property=”students” javaType=”ArrayList”
offType=”Student” column=”id” select=”getStudentByTId”/>
<select id=”getStudentByTId” resultType=”Student”>
select * from student where tid=#{id}
</select>按照结果嵌套查询
<select id=”getTeacher resultMap=”TeacherStudent”>
select s.id sid , s.name sname ,t.name tname, t.id tid
from student s, teacher t
where s.id = t.id and t.id = #{id}
</select>
<resultMap id =”TeacherStudent” type=”Teacher”>
<result property=”name” column=”tname”/>
<collection property=”students” ofType=”Student”>
<result property=”id”,column=”sid”/>
<result property=”name”,column=”sname”/>
<result property=”tid”,column=”tid”/>
</collection>
</resultMap>
小结
1. 关联 association 多对一,一对一
2. 集合 collection 一对多
3. JavaType ofType都用来指定对象类型的,JavaType指定pojo中属性的类型,ofType指定映射到list中pojo类型 动态SQL
指根据不同的查询条件,生成不同的SQL语句
if
choose(when,otherwise)
trim(where,set)
foreach
if
select * from company
where
<if test=”id != null”>
companyname=#{companyname}
</if>
where
select * from company
<where>
<if test=”id != null”>
companyname=#{companyname}
</if>
</where>
where标签会知道如果包含的标签有返回值,就插入”where”,如果返回的内容以AND或OR开头,就会剔除掉
Set
如果含有更新操作,使用set标签
update companyname
<set>
<if test=”id != null”>
companyname=#{companyname}
</if>
</set>
where id =#{id};
choose
有时候,我们不想用到所有查询条件,查询条件有一个满足即可,此时使用choose标签,类似swich语句
select * from company
<where>
<choose>
<when test=”id != null”>
and companyname=#{companyname}
</when>
<when test=”name != null”>
and companyid=#{companyid}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>缓存
什么是缓存
是存在内存中的临时数据,将用户经常查询的数据放在缓存(内存)中,用户查询时不用每次都从数据库中查询,提高查询效率,解决高并发性能问题
什么数据能使用缓存
经常查询并且不经常改变的数据
Mybatis缓存
系统默认定义了两级缓存:一级缓存和二级缓存
默认情况下,只有一级缓存开启,SqlSeesion级别的缓存,也成为本地缓存
二级缓存需要手动开启和配置,是基于namespace级别的缓存,Mybatis定义了缓存接口Cache,可以通过实现Cache接口实现二级缓存
一级缓存
一级缓存默认开启,与数据库同一次会话期间查询到的数据会放在本地缓存,再次获取时直接从缓存中获取,一级缓存有四种失效情况
1. SqlSession不同,每个SqlSession中的缓存相互独立
2. SqlSession相同,查询条件不同
3. SqlSession相同,但两次查询之间执行了增删改操作
4. SqlSession相同,但手动清除了一级缓存,session.clearCache()
二级缓存
只要开启了二级缓存,在同一个mapper中的查询都可以从二级缓存中拿数据
查出来的数据会默认先放在一级缓存
只有会话提交或关闭后,才会被转移到二级缓存
Spring
IOC
IOC控制反转是一种设计思想,DI依赖注入是实现IOC的一种方式。
没有IOC的程序中,我们使用面向对象编程,对象的创建与对象间的依赖关系完全硬编码在程序中,对象的创建由程序自己控制。控制反转指将对象的创建转移给第三方,获取依赖对象的方式反转了,IOC是Spring框架的核心内容,可以使用XML配置,注解实现ioc。
基本步骤
1. 创建pojo实体类 例如 创建实体MinaseInory
2. 编写spring文件,一般命名为bean.xml
bean就是java对象,由Spring创建和管理
<bean id=“MinaseInory” class=”com.zyq.wife. MinaseInory”>
<property name=”name” value=”Inory”>
</bean>
3. 使用
解析xml文件,生成管理相应的bean对象
AppliactionContext context = new ClassPathXmlAppliactionContext(“bean.xml”) ;
getBean:参数为spring配置文件中bean的id
MinaseInory inory = (MinaseInory)context.getBean(“inory”);
inory.定义的方法();
MinaseInory对象是由Spring创建的,属性也由Spring容器设置,这个过程就叫控制反转。
控制:谁来控制对象的创建,传统由程序本身,Spring由Spring
反转:程序本身不创建对象,而变成被动的接收对象
IOC是一种编程思想,由主动的编程变成被动的接收
特殊的创建方式:通过有参构造函数创建
通过根据index(构造函数)参数标(从零开始)/参数名/参数类型设置
标签<construcot-arg index/name/参数类型 value=“”>
依赖注入DI(Dependency Injection)
依赖:指Bean对象的创建依赖于容器,Bean对象的以来资源
注入:指Bean对象所依赖的资源,由容器来设置和装配
Set注入
根据实体类中的属性,在实体类生成get,set方法后
例如实体类MinaseInory中有name,age等属性
创建一个实体类Address(地址)
常量注入
<bean id =” MinaseInory” class=”com.zyq.wife. MinaseInory”>
<property name=”name” value=”水濑祈”/>
</bean>
bean注入
<bean id =” addr” class=”com.zyq.Address”>
<property name=”address” value=”郑州”/>
</bean>
<bean id =” MinaseInory” class=”com.zyq.wife. MinaseInory”>
<property name=”name” value=”水濑祈”/>
<property name=”address” ref=”addr”/>
</bean>
这里的ref表引用
数组注入
这里的数组是要定义在实体类中的
<bean id =” MinaseInory” class=”com.zyq.wife. MinaseInory”>
<property name=”name” value=”水濑祈”/>
<property name=”address” ref=”addr”/>
<property name=”friends”>
<array>
<value>佐仓绫音</value>
<value>内田真礼</value>
<value>种田梨纱</value>
</array>
</property>
</bean>
List注入
<property name=”hobbys”>
<list>
<value>玩游戏</value>
<value>追剧</value>
<value>看小说</value>
</list>
</property>
Map注入
<property name=”card”>
<map>
<entry key=”身份证” value=“xxxxxxxxxxxxx”/>
</map>
</property>
set注入
<property name=”games”>
<set>
<value>DBD </value>
<value>apex</value>
</set>
</property>
Bean的作用域
singleton
ioc容器中仅存在一个BEAN实例,以单例方式存在
创建起容器时就自动创建一个bean对象,不管是否使用也都存在,每次获取的都是同一个对象
<bean id=”ServiceImpl” class=”com.service.ServiceImpl”
scope=”singleton”>
prototype
每次从容器中调用BEAN时,都返回一个新的实例,即每次调用getBean()时,相当于执行 new XxBean(),prototype是原型类型,它在我们创建容器时并没有实例化,而是获取bean时才创建对象,并且我们每次获取到的对象都不是同一个对象,对有状态的bean应该使用prototype作用域,无状态的bean应该使用singleton
<bean id=”account” class=”com.zyq.Account” scope=”prototype”/>
或
<bean id=”account” class=”com.zyq.Account” scope=”false”/>
request:每次Http请求都会创建一个新的Bean,仅适用于WebAppliactionContext环境
session:同一个HTTP Session共享一个Bean,不同Session使用不同Bean,仅适用于WebAppliactionContext环境
Bean的自动装配
Bean的自动装配需要从两个角度来实现
1. 组件扫描:spring会自动发现应用上下文中所创建的bean
2. 自动装配:spring自动满足bean之间的依赖,依旧是IOC/DI
byName 按名字自动装配
手动配置xml,容易发生字母缺漏或大小写错误,自动装配会避免这些错误
使用方式:在bean标签中新增 autowire=“byName”
当一个bean节点带有autowire=“byName”属性时,spring会去查找类中所有set方法名,获得该方法名的字符串,如果spring容器中有,就取出注入,没有,报空指针异常
byType 按类型自动装配
需要保证同一类型的对象在spring容器中唯一,不唯一会报异常
NoUniqueBeanDefinitionException
使用方式:在bean标签中新增 autowire=“byType”
使用注解
首先要在spring配置文件中导入context文件头,开启注解支持
<context:annotation-config/>
@Autowired
根据类型自动装配,不支持id匹配,需要导入spring-aop包
@Autowird=ed(required=false),说明对象可以是null,true必须存对象
@Qualifier
结合 @Autowired使用,可以根据byName的方式自动装配
@Autowired
@Qualifier(value=”xxx”)
@Resource
如果含有指定的name属性,先按该属性查找装配,如果没有,按照默认的byName方式装配,如果还不成功,按照byType的方式进行装配
@Autowired与@Resource的异同
1. 二者都可以用来装配bean,都可以写在字段上或setter方法上
2. @Autowired默认按类型装配,默认情况下必须要求依赖对象存在,但特殊情况下可以有Null值,可以结合Qualifier实现按名称装配
3. @Resource默认按名称装配,可以通过name属性指定,如果没有指定,当注解写在字段上是,默认按字段名查找,如果写在setter方法上,默认取属性名装配,如果找不到名称匹配,按类型装配。
使用注解开发
spring4之后,使用注解需要导入aop的包并引入context约束
实际开发中,一般都会使用注解进行bean注入
首先配置扫描那些包下的注解
<context:component-scan base-package=”com.zyq”/>
在指定包下编写类,增加注解
@Component(“user”)
属性注入
可以不提供set方法,直接在字段名上添加@value(”值”)
如果提供了set方法, 也可以直接在set方法上添加
衍生注解
@Component三个衍生注解
@Controller:web层
@Service:service层
@Controller:dao层
代理模式
分为动态代理和静态代理
静态代理
角色分析
1. 抽象角色:一般使用接口或抽象类来实现,要做的行为
2. 真实角色:被代理的角色
3. 代理角色:代理真实角色,代理真实角色后,一般会做一些附属的操作
4. 客户:使用代理角色来进行一些操作
例子:出租房子
出租房子行为含有
Rent.java 租房,抽象角色,通常使用接口或抽象类
public interface Rent{
public void rent();
}
Host.java 房东,出租房子,真实角色
public class Host implements Rent{
public void rent(){
System.out.println("房屋出租");
}
}
Proxy.java 中介,代理角色
public class proxy implements Rent{
private Host host;
public Proxy(){}
public Proxy(Host host) {
this.host = host
}
//租房
public void rent(){
seeHouse();
host.rent();
fare();
}
//看房
public void seeHouse(){
System.out.println("带房客看房");
}
//
public void fare(){
System.out.println("收中介费");
}
}
Client.java 客户,租房子的人,要去找代理
public class Client{
public static void main(String[] args){
Host host = new Host();
Proxy proxy = new Proxy(Host)
proxy.rent();
}
}
在这个过程中,客户直接接触的只有代理类中介,根本开不到房东,但是依旧通过中介完成了租房子,这就是代理模式
静态代理的好处
1. 使得真实角色更加纯粹,不必关注一些公共的事情
2. 公共业务由代理来完成,实现了业务的分工
3. 公共业务在发生拓展时更加集中方便
缺点
多了一个代理类,工作量变大了,开发效率降低
在不改变原有代码的情况下对原有功能进行增强,这就是AOP中最核心的思想
动态代理
1. 动态代理的角色与静态代理一样
2. 动态代理的代理类是动态生成的,静态代理的代理类是提前写好的
3. 动态代理分为两类
基于接口的动态代理:JDK动态代理
基于类的动态代理:cglib
现在用的多的是javasist生成动态代理
JDK的动态代理需要了解两个类
核心:InvocationHandler与Proxy
InvocationHandler:是由代理实例的调用处理程序实现的接口,每一个代理实例都有一个关联的调用处理程序,当在代理实例上调用方法时,方法调用将被编码并分派到其调用处理程序的Invoke方法
Object invoke(Object proxy,方法 method,Object[] args);
proxy:调用该方法的代理实例
method:所诉方法对应于调用代理实例上的接口方法的实例,方法对象的声明类将是该方法声明的接口
args:包含的方法调用传递代理实例的参数值的对象的阵列,或Null,如果接口方法没有参数
Proxy:代理
提供了创建动态代理类和实例的静待方法,它也是由这些方法创建的所有动态代理类的超类,每一个代理实例都有一个关联的调用处理程序对象,它实现了接口InvocationHandler
代码实现
Rent.java 租房,抽象角色,通常使用接口或抽象类
public interface Rent{
public void rent();
}
Host.java 房东,出租房子,真实角色
public class Host implements Rent{
public void rent(){
System.out.println("房屋出租");
}
}
ProxyInvocationHandler.java 代理角色
public class ProxyInvocationHandler implements InvocationHandler{
private Rent rent;
public void setRent(Rent rent) {
this.rent = rent
}
//生成代理类,重点是第二个参数,获取要代理的抽象角色
public Object getProxy(){
return Proxy.newProxyInstance(this.getClass.getClassLoader(),
rent.getClass().getInterfaces(),this);
}
//proxy:代理类 method:代理类的调用处理程序的方法对象
@Override
public Object invoke(Object proxy , Method method, Object[] args)
throws Throwable {
seeHouse();
//核心:本质利用反射实现
Object result = method.invoke(rent , args);
fare();
return result;
}
//看房
public void seeHouse(){
System.out.println("带房客看房");
}
//
public void fare(){
System.out.println("收中介费");
}
}
Client.java 租客
public class Client{
public static void main(Sting [] args) {
//真实角色
Host host = new Host();
//代理实例的调用处理程序
ProxyInvocationHandler p= new ProxyInvocationHandler();
p.setRend(host); //将真实角色放入
Rend proxy = (Rent)p.getProxy();//动态生成对应处理类
proxy.rent();
}
}
核心:一个动态代理类,一般代理某一类业务,一个动态代理可以代理多个类,代理的是接口
优点
1. 静态代理有的好处,它都有
2. 一个动态代理一般代理一类业务
3. 一个动态代理可以代理多个类,代理的是接口
AOP
面向切面编程,通过预编译的方式和运行期动态代理实现程序功能的统一维护的一种技术,理用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间耦合度降低,提高程序可重用性
作用:提供声明式事务,允许用户自定义切面
关键字
Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些 Pointcut 以及相应的 Advice。
Joint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point。
Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方。
Advice(通知):Advice 定义了在 Pointcut 里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。
Target(目标对象):织入 Advice 的目标对象.。
Weaving(织入):将 Aspect 和其他对象连接起来, 并创建 Adviced object 的过程
Spring中指出五种类型的Advice
前置通知 方法前
后置通知 方法后
环绕通知 方法前后
异常抛出通知 方法抛出异常
引介通知 类中增加新的方法属性
即AOP在不改变原有代码的情况下,增加新的功能
简单理解
让我们来假设一下, 从前有一个叫爪哇的小县城, 在一个月黑风高的晚上, 这个县城中发生了命案. 作案的凶手十分狡猾, 现场没有留下什么有价值的线索. 不过万幸的是, 刚从隔壁回来的老王恰好在这时候无意中发现了凶手行凶的过程, 但是由于天色已晚, 加上凶手蒙着面, 老王并没有看清凶手的面目, 只知道凶手是个男性, 身高约七尺五寸. 爪哇县的县令根据老王的描述, 对守门的士兵下命令说: 凡是发现有身高七尺五寸的男性, 都要抓过来审问. 士兵当然不敢违背县令的命令, 只好把进出城的所有符合条件的人都抓了起来.
来让我们看一下上面的一个小故事和 AOP 到底有什么对应关系.
AOP中,Joint point(连接点)指所有方法中可以织入通知的地方,而point cut(切点)是一个描述信息,修饰连接点,通过切点,可以确定到底那些连接点需要被织入Advice(通知)。
连接点(joint point):县城中的所有百姓,出现命案,所有百姓都可能是嫌疑人,都有可能跟被审问(通知Advice)
切点(point cut):限定有那些连接点要被审问(织入通知)。例子中提到:身高约七尺五寸,这就直接限定了县城中所有身高七尺五寸的百姓(连接点),限定了范围
通知(Advice):审问。这是一个动作(功能),作用于被切点限定的连接点上。
切面(Aspect)是切点与通知的组合,比如,根据一个百姓提供的现所,凡是身高七尺五寸的人(切点),都要被抓起来审问(通知),这就相当于一个切面。
SpringMVC
什么是MVC
M:model,数据模型,提供要展示的数据,包含数据和行为,现在一般分为DAO和Service
V:view,负责进行模型的展示,一般就是我们见到的用户界面
C:controller,接受用户请求,委托给M层处理,处理完毕后将返回的模型数据返回V,由V负责展示
MVC框架要做的事情
1. 将url映射到java类的方法
2. 封装用户提交的数据
3. 处理请求,调用相关的业务处理,封装响应数据
4. 将相应的数据进行渲染 jsp/html
Spring的web框架围绕DispatcherServlet设计,它的作用是将请求分发到不同的处理器。
原理
当发起请求时被前置控制器拦截到请求,根据请求参数生成代理请求,找到请求对应的实际控制器,控制器处理请求,创建数据模型,访问数据库,将模型相应给中心控制器,控制器使用模型与视图渲染视图结果,将结果返回给中心控制器,再返回给请求者
步骤
1. 新建一个web项目
2. 导入相关jar包
3. 编写web.xml,注册DispatcherSerlet
4. 编写springmvc配置文件
5. 创建对应的控制类,controller
6. 完善前端视图和controller之间的对应
必须配置的三大类
处理器映射器,处理器适配器,视图解析器
通常只需要手动配置视图解析器,其他只需要开启注解驱动即可
controller和restful
控制器Controller
负责提供访问应用程序的行为,通常通过接口或注解定义
负责解析用户的请求并将其转换成一个模型
在springmvc中一个控制器可以包含多个方法
在springmvc中对于controller的配置方式有很多种
实现controller接口
这是比较老的方法,缺点是一个控制器中只有一个方法,如果要多个方法就需要定义多个controller,不推荐
使用注解@Controller
用于声明Spring类的实例是一个控制器
spring可以使用扫描机制来找到应用程序中所有基于注解的控制器类,需要在配置文件中声明组件扫描,交给ioc容器管理
使用方式:在类上加上@Controller注解
RequestMapping
@RequestMapping
用于映射url到控制器类或一个特定的处理程序方法,可以用于类或方法上,用于类上,类中所有响应请求地址都以该地址为父地址。
@Controller
public class TestController {
@RequestMapping("/h1")
public String test(){
return "test";
} }
访问路径:http://localhost:8080 / 项目名 / h1
@Controller
@RequestMapping("/admin")
public class TestController {
@RequestMapping("/h1")
public String test(){
return "test";
} }
访问路径:http://localhost:8080 / 项目名 /admin/ h1
所有地址栏请求默认都会是Http Get类型的
结果跳转方式
ModelAndView
设置ModelAndView对象,根据view的名称,和视图解析器跳到指定的页面。
ModelAndView mv = new ModelAndView();
mv.addObject(“msg”,”Controller”);
mv.setViewName=(”test”);
return mv;
整合SSM
环境搭建
1. 导入相关pom依赖
2. Maven资源过滤
3. 基本结构和配置框架
pojo 实体类
dao 持久层
service 业务层
controller 控制层
4. 相关配置文件
mybatis-config.xml
applicationContext.xml
Mybatis层的编写
数据库配置文件 database.properties
jdbc.driver=……
jdbc.url=…..
jdbc.username=….
jdbc.password=…..
IDEA关联数据库
编写Mabatis核心配置文件,将mapper注册进去
编写pojo实体类,编写构造函数,setget方法
编写dao层的mapper接口
编写接口对应的mapper.xml文件,编写sql语句
编写service层的接口和实现类 service和serviceimpl
至此,mybatis底层需求编写完毕
配置Spring整合mybatis
编写配置文件 spring-dao.xml
配置数据库连接池(dbcp半自动化,不能自动连接,c3p0相反)
配置datasource数据源,结合上面写的datasource.properties
配置SqlSessionFactory对象
配置扫描DAO接口包,动态实现DAO接口注入到spring容器
整合service层
扫描service相关的bean
将实现类注入到ioc容器
配置事务管理器,注入数据库连接池
至此,spring层结束,它就是一个容器
SpringMVC
配置web.xml
注册DisPatcherServlet
配置spring-mvc.xml
1. 开启springmvc注解驱动
2. 静态资源默认servlet配置
3. 配置jsp,显示视图解析器
4. 扫描web相关的bean
spring配置整合文件,appliactionContext.xml
JSON
JSON是一种轻量级数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据
JSON键值对是用来保存js对象的一种方式,JSON 是 JavaScript 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。
SpringBoot
这个其实没什么好说的,既然是初级程序员,最常问的就是SpringBoot和Spring的常用注解
如果问你自动配置原理,只用围绕@AutoConfiguration 这个注解,因为深入到源码你估计也记不住,就算真背下来了面试官故意恶心你往深问一点你就无了,所以干脆就说到这,再问就是记不清,不知道。还有,如果遇到有面试官问你SpringBoot和SpringCloud区别是啥,基本上就可以考虑下一家,这问题实在太蠢,没回答的必要,
@AutoWired @Controller... @Bean @Configuration @Value @Aspect
@AutoConfiguration @SpringBootApplication @ResponseBody
@RequestMapping @Import
Linux
绝对路径:/etc/init/
当前目录:./ 上层目录 ../
主目录:~/
切换目录:cd
当前进程:ps
执行退出:exit
查看当前路径:pwd
清屏:clear
退出当前命令:ctrl+c
列出指定目录中的目录:ls
查看文件
vi 编辑方式查看,可修改
cat 显示全部文件内容
more 分页显示文件内容
less 与more相似,可以翻页
tail 只查看尾部,可以指定行数
head 只查看头部,可以指定行数
创建目录:mkdir
移除目录:rmdir 连目录及目录下文件一起删除 rm -r
打包:tar -xvf
打包并压缩:tar -zcvf
查找字符串:grep
创建空文件:touch
编辑器:vim vi
移动文件:mv
查看ip地址及接口信息:ifconfig
查看环境变量:env
Redis
C: Consistency(强一致性)
A: Availability(可用性)
P: Partition tolerance(分区容错性)
默认16个数据库,0-15,默认使用第0号数据库
常用命令
select:切换数据库 select 7 切换到第7个数据库
Dbsize:查看当前数据库key的数量
Flushdb:清空当前数据库
Flushall:清空全部数据库
keys * :查看所有的key
exists keyname:判断keyname是否存在
move key db:移除当前库
expire key 秒数:给kay设置生存时间,到期会自动删除
ttl key :查看Key还有多少秒过期,-1永不过期,-2已过期
type key:查看这个key的类型Redis是基于内存操作的单线程数据库,多线程的本质是CPU模拟出多个线程,上下文切换要消耗时间,redis用单个CPU绑定一块内存的数据,针对这个数据进行读写时都在一个cpu上完成,无需切换上下文,也就是说在做一个事情的时候,这个事情没有完成时,会同时去做别的事情,所以即使单线程也很快。
五大数据类型
String
动态字符串,是Redis最基本的数据类型,1M以下的字符串如果需要扩容会扩容一倍,1M以上会一次扩容1M,最大不能超过512M
List
简单的字符串链表,按照插入顺序排序,底层是双链表,可以插入数据到头部或尾部
Set
String类型的无序集合,通过HashTable实现
Hash
哈希,类似HashMap,键值对集合,是一个String类型的field和value映射表,特别适合存储对象。类似java中的Map(String,Object)
Zset
String类型的无序集合,不允许重复,每个元素都会关联一个double类型的分数,Redis通过分数为集合中的数据从小到大排序,Zset成员是唯一的,但分数是可以重复的
字符串String
常用命令
set key1 value1 设置值
get key1 获取值
del key1 删除值
keys * 查看所有key
exists key1 查看key1是否存在
append key1 “hello” 如果key1不存在,相当于set一个value为hello的key1,如果key1存在,相当于在后面添加hello
strlen key1 查看key1的长度
incr/decr key1给key1的数字+1/-1,key1必须是数字
incr/decr by key1 10 加10,10可以是任意数
getrange key1 0~n,截取0~n区间key1的字符串,n=-1代表全部
setrange key1 1 xx 把key1 1位置上的字符替换成xx,123变成1xx3
setex key1 n秒 expire 设置key1过期时间
ttl key1 查看剩余时间
setnx key1 value 如果key1不存在就设置,返回1,存在就返回0,值不变
mset key1 v1 key2 v2 key3 v3同时设置一个或多个kv键值对
mget 同时获取一个或多个键值对,获取不到,返回nil
msetnx 原子性同时设置一个或多个kv键值对,一个设置失败就全部失败,原子性
getset key1 v1 先get再set 没有旧值,返回nil列表List
简单的字符串列表,按照插入顺序排序,可以添加数据到头或尾,底层是双链表,对两端操作性能很高
常用命令
lpush/rpush,从左/右边插入一个或多个数值
lpush k1 v1 v2 v3 从左边加入名字是k1,值是v1.v2.v3三个值
读取
1.v3
2.v2
3.v1
先放v1,放v2把v1往右挤一位,放v3把v2往右挤一位,所以顺序是v3,v2,v1
rpush k2 v1 v2 v3
读取
1.v1
2.v2
3.v3
相当于把左push反过来
lpop/rpop k1从k1左边/右边拿出一个值,值拿光后键就没了
lpop k1 取出v1,rpop k1返回k3,此时k1的value只剩v2,取出后k1就消失了
rpoplpush k1 k2 从k1右边拿出一个值插入到k2左边
原 k1 值顺序v3 v2 v1 k2 v1 v2 v3,执行后变成k2变成 v1(k1) v1 v2 v3
lrange key 0 n 获取元素(从左到右)
lrange k2 0 -1
1. v1(k1拿过来插入的)
2. v1(原来的)
3. v2
4. v3
lindex k2 n 根据下标获取列表的元素(从左到右)
lindex k2 0 返回v1(从k1拿来的)
llen k2获取列表长度
linsert k2 before/after value new value 在k2 的value前/后插入新值
linsert k2 v2 before newv2
lrange k2 0 -1 返回
1. v1(拿来的)
2. v1
3. newv2
4. v2
5. v3
lrem k2 n value 从左边删除n个value
lrem k2 2 v1 删除两个v1
lrange k2
1. newv2
2. v2
3. v3
lset k2 n value 将k2第n个位置的数据替换成value
lset k2 1 v587
lrange k2 0 -1
1. newv2
2. v587
3. v3List的数据结构为快速链表quickList
在列表元素较少的情况下会使用一块连续的内存存储,结构是ziplist
当数据变多时,会将多个ziplist结合起来组成quicklist,既满足快速插入,又不会有太大的空间冗余
集合Set
是个类似list的列表功能,特殊在于能自动排重,是string类型的无序集合,底层是hash表,可以快速定位数据
常用命令
sadd k1 v1 v2添加一个或多个元素
smembers k1 取出k1的所有值
sismembers k1 value 判断k1中是否有这个value
scard k1 返回k1的元素个数
srem k1 v1 v2 删除k1中的v1,v2
spop k1随机从k1中取出一个值,取完键消失
srandmember k1 n 从k1中取出n个值,不会将其从k1中删除
smove k1 k2 v1把k1的v1移动到k2,k1中v1消失
sinter k1 k2 取k1 k2的交集
sunion k1 k2 取k1 k2 的并集(所有)
sdiff k1 k2 取k1 k2的差集(k1中有,k2没有)
set数据结构是dict字典,通过哈希表实现,通过哈希表能快速找到对象
哈希Hash
键值对集合,field和value的映射表,最适合存储对象。
key value
user id,123456
name,张三
常用命令
hset k1 field value 给k1中添加数据(就像是嵌套一个kv键值对)
hset k1 name inory 向k1添加field属性为name 值为inory的数据
hget k1 field 从k1中取出指定field的数据
hget k1 name 返回 “inory”
hmset k1 field 1 value 1 field 2 value2 给k1中批量加入hash值
hexists k1 field 判断k1中指定field是否存在
hkeys k1 列出k1中所有的field
hvals k1 列出k1中所有的value
hincrby k1 field n 给k1中指定field的值加上n
hsetnx k1 field n 给k1中指定field 添加值 有则不能添加Hash类型对应的数据结构是ziplist压缩列表,hashtable哈希表,field-value短且少,用ziplist,大且多用hashtable
有序集合Zset
与set相似,是一个没有重复元素的字符串集合。每一个成员都关联一个分数,根据分数从小到大排序,成员唯一,分数不唯一
常用命令
zadd k1 n java n+1 c++ n+2 mysql 将一个或多个分数与成员添加
zrange k1 0 -1 取出k1所有内容,排名根据分数从小到大排序
zrange k1 0 -1 withscores 取出内容并返回分数
zrangebyscore k1 x y 取出k1分数在x,y之间的数据
zrevrangebyscore 根据分数从大到小排序(反转)
zincrby k1 n value 给k1指定value加上n
zrem k1 value删除k1指定value
zcount k1 x y 统计k1中分数在x,y之间所有元素
zrank k1 value 返回k1中指定value的排名,从0开始数据结构
zset比较特别,一方面等于Map<String,Double>(值和分数),另一方面等于TreeSet,内部元素会根据分数排序,可以得到每个元素的排名,也可以通过分数的范围获取元素列表
zet底层使用两个数据结构
1. hash,关联元素value与分数score,保障元素唯一性,可以通过value找到对应的score
2. 跳跃表,目的在于给value排序,根据分数范围获取元素列表
跳跃表效率比普通表高。普通有序链表需要一个一个找,从头开始直到找到,跳跃表分层查找,大范围比较大小实现较少的查询次数。
redis只支持bite,不支持bit,不区分大小写
发布和订阅pub/sub
是一种消息的通信模式
发布者:发布信息
订阅者:订阅发布者的信息,接受发布者的消息
Redis客户端可以订阅任意数量的频道
打开一个客户端订阅一个频道
subscribe channel1
打开另一个客户端给channel1发送消息
publish channel 123456
第一个客户端就能接受信息
只有订阅的频道才能收到消息,没订阅就收不到
Redis新数据类型
Bitmaps
用二进制(位)作为信息的基础单位,1个字节等于8位,合理的使用操作位可以有效地提高内存使用率和开发效率。
Bitmaps本身不是一种数据类型,实际上就是字符串,但他可以对字符串的位进行操作。可以把Bitmaps想象成一个以位为单位的数组,每个单元只能存储0和1,数组的下标成为偏移量。
命令
setbit key1 offset value offset 偏移量,存放类似id
setbit k1 1998 1 往k1里面添加值为1,偏移量为1998的数据
getbit k1 1998取出k1中偏移量为1的数据
bitcount k1 统计value被设置成1的元素数
bitop 复合操作Bitmap相比于set能节省空间,但活跃用户少的时候不适合用,会出现一堆0
HyperLogLog
处理基数问题过多(基数,指一个集合中不重复的元素,基数问题指求集合中不重复元素的个数)
处理方案:mysql count(1) redis hash set bitmaps
但数量太大占用空间会越来越大
HyperLogLog优点在于输入元素数量或体积非常大时,计算基数所需的空间总是固定的且很小,每个HyperLogLog只需花费12KB内存,就可以计算接近2的64次方个不同元素的基数。
它只会根据输入元素计算基数,不会储存输入元素,所以不能返回输入的元素。
命令
pfadd k1 “java” 加入一个或多个元素 添加会自动去重
pfcount k1 统计出基数的数量
pfmerge k3 k1 k2 将k1,k2中的基数合并到k3中Geospatial
地理信息的缩写,经纬度,针对经纬度的相关查询
geoadd k1 经度 纬度 名称 添加一个或多个城市的经纬度
两级无法直接添加,有效经度-180-180,维度-85-85,超出的会返回错误,已添加无法继续添加
geoadd k1 121.47 31.23 shanghai
geopos k1 名称 取出经纬度
geopos k1 shanghai
geodist k1 名称1 名称2 单位 查找两个地方的距离,如果有一个不存在,返回空值,可以指定单位(m,km,mi英里,ft英尺),不指定默认是米,最大误差0.5%。
georadius k1 经度 纬度 n m/km/tf/mi 返回距中心半径为n的城市
georadius k1 100 30 1000km 返回距100,30半径为1000km的城市
后面加withdist返回中心距离,withcoord返回经纬度 count限定个数
georadiusbymemeberRedis持久化
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,一旦服务器退出,服务器中的数据库状态也会消失
RDB(Redis DataBase)
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是SnapShot,它恢复时是将快照直接读取到内存中。
Redis会单独创建(fork)一个子进程来进行持久化,先将数据写入一个临时文件,到持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中主进程不进行任何IO操作,这确保了极高的性能,如果需要进行大规模数据恢复,且对于数据恢复的完整性不是非常敏感,RDB方式比AOF方式更高效,RDB的缺点在于最后一次持久化后的数据可能丢失
Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据都和原进程一致,但是是一个全新的进程,作为原进程的子进程。
RDB是整合内存的压缩过的SnapShot,RDB的数据结构,可以配置符合的快照触发条件,默认1分钟改1万次,5分钟内改10次,15分钟内改1次,如果想要禁用RDB持久化策略,只要不设置save指令,或者给save传一个空字符串参数也可以。
如何触发RDB快照
1. 配置文件中默认的快照配置,建议备份复制一份dump.rdb
2. 命令save或bgsave
3. 执行flushall,会产生空的dump.rdb
4. 退出时会产生
如何恢复
将dump.rdb移动到redis安装目录并启动服务即可。
config get dir获取目录
优点
1. 适合大规模的数据恢复
2. 对数据的完整性和一致性要求不高
缺点
1. 在一定间隔时间做一次备份,如果redis意外终止,会丢失最后一次快照后的所有修改
2. Fork时内存中的数据被克隆了一份,会膨胀大概两倍
RDB是一个非常紧凑的文件,在保存RDB文件时父进程唯一要做的就是fork出一个子进程,接下来全部工作由子进程做,父进程不需要再做其他IO操作,所以能最大化Redis性能,恢复大数据集比AOF快,但数据丢失风险大,需要经常fork子进程保存数据集到硬盘,数据集大的时候fork会很耗时。
AOF(Append Only File)
以日志的形式来记录每个写操作,将Redis执行过的所有(写)指令记录下来,只允许追加文件但不能改写文件,redis启动之初会读取该文件重新构建数据,也就是说Redis重启时会根据日志文件的内容将写指令从前往后执行一遍以完成数据的恢复工作
AOF保存的是appendonly.aof文件
AOF启动/修复/恢复
正常恢复
1. 启动:设置YES,修改默认的appendonly no,改为yes
2. 将有数据的aof文件复制一份保存到对应目录(config get dir)
3. 恢复:重启redis然后重新加载
异常恢复
1. 设置yes
2. 故意破坏appendonly.aof文件
3. 修复 redis-check-aof –fix appendonly.aof 进行修复
4. 重启redis然后重新加载、
Rewrite
AOF采用文件追加方式,文件会越来越大,新增了重写机制,当AOF文件的大小超过设定阈值时,Redis会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof
重写原理
AOF文件持续增长而过大时,会fork出一条新进程将文件重写,遍历新进程的内存中数据,每条记录有一条set语句。重写aof文件的操作,并没有读取旧的aof文件。
触发机制
Redis会记录上次重写时AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且大于64M时触发
优点:
1. 每修改同步:同步持久化,每次发生数据变更会立即记录到磁盘,性能较差但数据完整性好
2. 每秒同步:异步操作,每秒记录,如果在一秒内宕机,有数据丢失
3. 不同步:从不同
缺点
1. 相同数据集的数据而言,aof文件远大于rdb文件,恢复速度慢于rdb。
2. AOF运行效率慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同。
AOF文件是一个只进行追加的日志文件,Redis可以在AOF文件体积过大时自动在后台对AOF进行重写,它有序的保护了对数据库执行的所有写入操作,以Redis协议格式保存,易懂易分析,但体积通常大于RDB文件,所用的fsync策略让其速度可能慢于RDB
总结
1. RDB持久化方式能在指定时间间隔对你的数据进行快照存储
2. AOF持久化方式记录每次对服务器写的操作,重启时会重新执行这些命令来恢复原始数据,命令以Redis协议格式追加保存到文件末尾,Redis可以对AOF文件重写来保证文件体积不会过大
3. 只做缓存,如果只希望数据在服务器运行时存在,可以不用持久化
4. 同时开启两种持久化方式,redis重启时会优先载入AOF文件恢复原始数据,因为通常AOF会比RDB完整,RDB数据不实时,同时使用时服务器重启也只会找AOF文件,但RDB更适合备份数据库(AOF不断变化不好备份)快速重启,且不会有AOF可能潜在的BUG。
5. 性能建议
RDB文件只做后备用途,建议只在Slave上持久化RDB文件,15分钟备份一次,只保留save 900 1这条规则。
如果Enable AOF,好处是在恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自 己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite过程中产 生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite 的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。
如果不Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大笔IO,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时挂掉,会丢失十几分钟的数据, 启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。
Redis事务
概念
Redis事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中的所有命令都会被序列化,在执行过程中,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入进序列
Redis事务就是一次性,顺序性,排他性的执行一个队列中的一组命令。
Redis事务没有隔离级别的概念,不保证原子性,没有回滚,事务中任意命令执行失败(运行错误),其他命令仍会被执行,但命令入队前,redis会对命令进行检查,如果命令不存在或参数不对,语法错误,所有命令不会被执行。事务有三个阶段:开始事务,命令入队,执行事务。
相关命令
watch key1 key2 监视一个或多个key,事务执行前被监视的key被其他命令改动,则事务被打断
mult1标记一个事务块的开始
exec 执行所有事务块的命令,一旦执行,监控锁会全部取消
discard 取消事务,放弃全部命令
unwatch 取消对所有key的监控
流程
正常执行
MULTI 开启事务
//命令入队
set k1 v1
set k2 v2
get k2
set k3 v3
EXEC 执行事务
//返回结果
1. OK
2. OK
3. V2
4. OK
放弃事务
MULTI 开启事务
//命令入队
set k1 v1
set k2 v2
get k2
set k3 v3
DISCARD 取消事务
如果事务队列中存在命令性错误(编译性错误),执行EXEC命令时所有命令不会执行,例如set k3 v3 后又getset k3 因为k3已经存在,会发生错误
如果存在语法错误,错误语句不会执行,其他命令正常执行,例如set k1,v1后incr value不是数字的v1
Watch监控
悲观锁
每次拿数据都认为会被别人修改,所以每次拿数据时都会上锁。
乐观锁
每次拿数据都认为别人不会修改,所以不上锁。但更新时会判断一下在此期间有没有人更新这个数据,可以提高吞吐量,提交版本必须大于记录当前版本才能执行更新
一旦执行EXEC开启事务的执行,无论事务是否执行成功,watch对变量的监控都会被取消。
Redis主从复制
概念
将一台Redis服务器的数据复制到其他Redis服务器。前者称为主节点(master/leader),后者是从节点(slave/follower),数据的复制是单向的,只能从主到从,master以写为主,slave以读为主
默认情况下,每台Redis服务器都是主节点,一个主节点可以有多个从节点,一个从节点只有一个主节点。
主从复制的作用主要包括:
1. 数据冗余:实现了数据热备份,是持久化之外的一种数据冗余方式
2. 故障恢复:主节点出现问题,可由从节点提供服务,实现故障快速恢复,实际上是服务的冗余
3. 负载均衡:主从复制的基础上配合读写分离,可以由主节点提供写,从节点提供读,分担服务器负载。在写少读多时通过多个从节点分担读负载,大大提高服务器并发量
4. 高可用基石:主从复制还是哨兵和集群能实施的基础,是高可用的基础
复制原理
slave启动成功连接到master会发送一个sync命令,master拿到命令后启动后台的存盘过程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后将传送整个数据文件到slave并完成一次同步。
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
只要是重新连接master,会自动执行一次全量复制
哨兵模式
能够后台监控主机是否故障,如果故障根据投票数自动将从库转换为主库。哨兵是一种特殊模式,Redis提供哨兵的命令,它是一个独立进程,会独自运行,原理是哨兵通过发送命令等待Redis服务器相应,从而监控运行的多个Redis实例
它通过发送命令监控主从服务器运行状态,当检测到master宕机会自动将slave切换成master,通过发布订阅模式通知其他从服务器修改配置文件,切换主机,为了防止一个哨兵进程出现问题,往往使用多个哨兵进程,形成多哨兵模式,哨兵之间也会互相监控,假如主服务器宕机,哨兵1检测到,系统不会马上切换主从,这是主观下线,后面的哨兵也检测到后,哨兵间会进行投票,由一个哨兵发起,进行转移,切换成功后发布订阅模式,让其他哨兵把监控的从服务器切换成主服务器,这是客观下线。
优点:
1. 哨兵集群模式基于主从模式,拥有主从模式的优点
2. 主从可以切换,故障可以转移,可用性好
缺点
1. Redis较难支持在线扩容,在集群容量达到上限在线扩容很复杂
2. 实现哨兵模式的配置不简单,比较繁琐
缓存穿透与雪崩
Redis缓存极大的提升了应用程序的性能与效率,但是数据一致性得不到保证,如果需要较高的一致性,不能使用缓存。
缓存穿透
用户想要查一个数据,redis内存数据没有,缓存没有命中,于是向持久层数据库查询,也没有,本此查询失败,这是一次未命中。当多个用户产生多次未命中,会给持久层数据库带来很大的压力,这就相当于出现了缓存穿透
解决方法
布隆过滤器
这是一种数据结构,对所有可能查询的参数都以hash形式存储,在控制层先进行校验,不符合则丢弃,避免了对底层存储系统的查询压力
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存,同时设置一个过期时间,再访问这个数据会从缓存中获取,保护了后端数据源。
但这两种方式也会出现问题,如果空值能被缓存,这意味着需要更多空间存储更多的键,即使设置了过期时间,还是会存在缓存层和存储层数据有一段时间窗口的不一致,这对需要保持一致性的业务有影响
缓存击穿
缓存击穿是指一个key非常热门,不停的扛着高并发,集中这一个key访问。这个key失效的瞬间持续的高并发会击破缓存,直接请求数据库,由于缓存过期,会访问数据库查询最新数据回写缓存,导致数据库瞬间压力过大
解决方法
设置热点数据永不过期
不让他过期就完事了
加互斥锁
使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限。这种方式将高并发压力转移到了分布式锁,对其考验很大
缓存雪崩
指在某一个时间段,缓存集中过期失效/
例如一批数据设置缓存1小时,1小时后这批数据集体过期,对这批数据的访问压力就来到了数据库上,产生周期性的压力波峰,存储层的调用量会飙升,造成存储层挂掉的情况。集中过期并不是非常致命,致命的是某个节点宕机或断网,可能瞬间压垮数据库
解决方法
Redis高可用
既然redis可能挂,我多整几台,一台挂了其他的可以继续用,搭建集群
限流降级
缓存失效后,通过加锁或队列控制读数据库写缓存的线程数量,对一个key只允许一个线程读写,
数据预热
正式部署前,把可能的数据预先访问一遍,这样可能大量访问的数据会加载到缓存中,设置不同的过期时间,让缓存失效的时间尽量均匀
Jedis
官方推荐java连接的开发工具。
常用API见文档
跨域问题
什么是跨域
浏览器从一个域名的网页去请求另一个域名的资源时,域名,端口,协议任一不同,都是跨域。
端口和协议的不同,只能通过后台解决,localhost和127.0.0.1虽然都指向本机,但也是跨域
跨域限制
无法读取非同源网页的cookie,localStorage,indexedDB
无法接触非同源网页的DOM
无法向非同源地址发送AJAX请求,可以发送但浏览器会拒绝接受相应
如何解决跨域问题
1.jsonp跨域
JSONP(JSON with Padding:填充式JSON),应用JSON的一种新方法
JSON与JSONP的区别
JSON返回的是一串数据,JSONP返回的是脚本代码(包含一个函数调用)
JSONP只支持get请求,不支持post请求(类似往页面添加一个script标签,通过src属性去触发对指定地址的请求,只能是Get请求)
2.nginx反向代理
www.baidu/index.html需要调用www.sina/server.php,可以写一个接口www.baidu/server.php,由这个接口在后端去调用www.sina/server.php并拿到返回值,然后再返回给index.html
3.PHP端修改header
header(‘Access-Control-Allow-Origin:*’);//允许所有来源访问
header(‘Access-Control-Allow-Method:POST,GET’);//允许访问的方式
若依框架
0.分页实现
mybatis轻量级分页插件pageHelper
在Controller添加 startPage();配合前端完成自动分页
注意:
1.如果要分页的list中存在null值,pageHelper会产生一个分页参数,但不会被消费,就会一直保留在这个线程上。当这个线程被再次启动时,会消费这个参数,导致分页。所以在分页时要对数据进行非空判断,非空时再分页。
2.startPage()只对该语句后的第一个查询(select)语句得到的数据分页,所以一定要把要分页的查询语句写在它后面。
1.导入导出
@Excel
1. 在实体类变量上加@Excel注解
举例:
@Excel(name = "用户序号", prompt = "用户编号")
private Long userId;
2.在Controller添加导出方法
ExcelUtil<User> util = new ExcelUtil<User>(User.class);
return util.exportExcel(list, "用户数据");
2.上传下载
代码生成数据库表相关代码并复制到对应目录
FileInfoController中添加对应上传方法
// 上传文件路径
String filePath = RuoYiConfig.getUploadPath();
// 上传并返回新文件名称
String fileName = FileUploadUtils.upload(filePath, file);
fileInfo.setFilePath(fileName);
return toAjax(fileInfoService.insertFileInfo(fileInfo));
yml中multipart可以实现对文件格式控制
# 文件上传
servlet:
multipart:
# 单个文件大小
max-file-size: 10MB
# 设置总上传的文件大小
max-request-size: 20MB
单纯上传无参数的图片有通用方法 /common/upload
文件下载
/**
* 本地资源通用下载
*/
@GetMapping("/common/download/resource")
public void resourceDownload(String resource, HttpServletRequest request, HttpServletResponse response)throws Exception
{
// 本地资源路径
String localPath = Global.getProfile();
// 数据库资源地址
String downloadPath = localPath + StringUtils.substringAfter(resource, Constants.RESOURCE_PREFIX);
// 下载名称
String downloadName = StringUtils.substringAfterLast(downloadPath, "/");
response.setCharacterEncoding("utf-8");
response.setContentType("multipart/form-data");
response.setHeader("Content-Disposition",
"attachment;fileName=" + FileUtils.setFileDownloadHeader(request, downloadName));
FileUtils.writeBytes(downloadPath, response.getOutputStream());
}
权限注解
@shiro权限控制注解
有优先级顺序,类似事务的原子性,前面的不通过就直接返回,前面通过了再看后面,同时声明就同时起作用。
@RequiresRoles
当前Subject必须拥有指定角色,默认是logical = Logical.AND,意为同时拥有
@RequiresRoles("admin") 必须有admin角色
@RequiresRoles({"admin", "common"}) 必须同时有admin角色和common角色
@RequiresRoles(value = {"admin", "common"}, logical = Logical.OR)
admin角色与common角色有一个就行
@RequiresPermissions
当前Subject必须拥有某些特定权限,默认是logical = Logical.AND,同时拥有,基本设定同上
@RequiresPermissions("system:user:add")
@RequiresPermissions({"system:user:add", "system:user:update"})
@RequiresPermissions(value = {"system:user:add", "system:user:update"}, logical = Logical.OR)
@RequiresAuthentication
当前Subject必须在当前session中已经过认证
@RequiresUser
当前Subject必须是应用的用户
@RequiresGuest
当前Subject可以是guest身份,不需要经过认证或在原先session中存在记录
事务管理
@Transactional,加在方法或类上
只能用在public修饰的方法上,可以被用在接口定义和接口方法,方法会覆盖类上面声明的事务。
优势体现在事务的ACID原则,原子性可以防止脏数据的产生,一个事务中如果一个操作出现错误,所有操作都会进行回滚。
注意:spring中事务默认只在运行时异常和程序出错时才回滚,在事务中声明检查异常不会回滚,如果需要,这样做@Transactional(rollbackFor = Exception.class)
不要在业务层用try catch捕捉异常,直接抛出交给控制层处理。
事务的传播
事务的传播机制指在开始当前事务前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。指在执行一个被@Transaction标记的方法时,开启了事务。在该方法在执行中时,另一个人也触发了该方法,这时可以通过事务的传播机制指定处理方式。
TransactionDefinition 传播行为的常量
TransactionDefinition.PROPAGATION_REQUIRED 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。
TransactionDefinition.PROPAGATION_REQUIRES_NEW 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_SUPPORTS 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER 以非事务方式运行,如果当前存在事务,则抛出异常。
TransactionDefinition.PROPAGATION_MANDATORY 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
TransactionDefinition.PROPAGATION_NESTED 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
异常处理
异常很常见,如业务异常,权限不足,前端需要弹窗提示用户有什么问题。通常使用try catch进行异常捕捉,但较多的异常捕捉会导致代码繁杂,重复。我们希望代码专注于业务,所有异常都单独设立一个类来处理。全局异常就是对框架所有异常进行统一处理。
全局异常处理器:@ControllerAdvice @ResponseBody(返回json字符串格式) 如果全部异常信息都要返回成json格式,可以用@RestControllerAdvice代替@ControllerAdvice,可以省略@ResponseBody
参数验证
springboot可以用@Validated校验数据,数据出现异常会统一抛出异常,方便异常中心统一处理。
用法:在controller上加上该注解,在对应字段方法或实体类字段上加上需要的校验注解
@Xss 该字段是否存在跨站脚本工具
@Null 是否为空
@NotNull 不能为null
@NotBlank 不能为空,常用于检查字符串
@NotEmpty 不能为空,常用于检测List或size是0
@Max 该字段值只能<=该值
@Min 该字段值只能>=该值
@Past 该字段日期是否在过去
@Future 该字段日期是否在将来
@Email 该字段是否一个有效邮箱地址
@Pattern(regex=,flag=) 被注释的元素必须符合指定的正则表达式
@Range(min=,max=,message=) 被注释的元素必须在合适的范围内
@Size(min=,max=) 该字段的size是否在min和max之间,可以是字符串,数组,集合,map
@Length(min=,max=) 该字段长度是否在min和max之间,仅限字符串
@AssertTrue 用于boolean字段,只能为true
@AssertFalse 用于boolean字段,只能为false
自定义注解校验
上述注解都是原生写死的,可以自定义注解校验,如@Xss
自定义分组校验
在使用实体类的情况下更好的区分出新增,修改,和其他操作验证的不同,可以通过groups属性设置。
@NotNull(message = "不能为空", groups = {Add.class})
@NotBlank(message = "不能为空", groups = {Add.class, Edit.class})
系统日志
某些业务需要记录该操作的内容。一个操作调用一次记录方法,收集参数,会造成代码重复。
在需要被记录日志的controller方法上加@Log注解
@Log(title = "用户管理", businessType = BusinessType.INSERT)
public AjaxResult addSave(...)
{
return success(...);
}
注解参数说明
参数 类型 默认值 描述
title String 空 操作模块
businessType BusinessType OTHER 操作功能(OTHER其他、INSERT新增、UPDATE修改、DELETE删除、GRANT授权、EXPORT导出、IMPORT导入、FORCE强退、GENCODE生成代码、CLEAN清空数据)
operatorType OperatorType MANAGE 操作人类别(OTHER其他、MANAGE后台用户、MOBILE手机端用户)
isSaveRequestData boolean true 是否保存请求的参数
isSaveResponseData boolean true 是否保存响应的参数
数据权限
@DataSource
部门只能查看其指定部门的数据,其他部门的数据不能看,这就是数据权限。
默认的系统管理员admin拥有所有数据权限(userId=1),默认角色拥有所有数据权限(不需要数据权限不用设置数据权限操作)
注解参数说明
参数 类型 默认值 描述
deptAlias String 空 部门表的别名
userAlias String 空 用户表的别名
目前支持的权限
全部数据权限
自定数据权限
部门数据权限
部门及以下数据权限
仅本人数据权限
例如
1.@DataScope(deptAlias = "d") d表示表的别名
2.在mybatis查询底部标签添加数据范围过滤
<select id="select" parameterType="..." resultMap="...Result">
<include refid="select...Vo"/>
<!-- 数据范围过滤 -->
${params.dataScope}
</select>
未过滤权限sql
select u.user_id, u.dept_id, u.login_name, u.user_name, u.email
, u.phonenumber, u.password, u.sex, u.avatar, u.salt
, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by
, u.create_time, u.remark, d.dept_name
from sys_user u
left join sys_dept d on u.dept_id = d.dept_id
where u.del_flag = '0'
过滤权限sql
select u.user_id, u.dept_id, u.login_name, u.user_name, u.email
, u.phonenumber, u.password, u.sex, u.avatar, u.salt
, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by
, u.create_time, u.remark, d.dept_name
from sys_user u
left join sys_dept d on u.dept_id = d.dept_id
where u.del_flag = '0'
and u.dept_id in (
select dept_id
from sys_role_dept
where role_id = 2
)
后面那个嵌套查询就是数据权限过滤
实体只有继承BaseEntity才会处理,sql语句会存放到BaseEntity对象中的params属性中,然后通过xml中的${params.dataScope}获取拼接后的语句
多数据源
开发中会遇到一个应用可能要访问多个数据库的情况,项目中使用注解完成此功能
在需要被切换数据源的Service或mapper方法上添加@DataSource注解
@DataSource(value = DataSourceType.MASTER)
value表示数据源名称,除MASTER和SLAVE其他都需要配置
使用方式
1.在yml配置文件中配置slave从库数据源
2.在DataSourceType类添加数据源枚举
3.在DruidConfig配置读取数据源
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
4.在DruidConfig类dataSource方法添加数据源
setDataSource(targetDataSources, DataSourceType.SLAVE.name(),"slaveDataSource");
5.在需要多数据源方法或类上添加@DataSource注解,value表示数据源
@DataSource(value = DataSourceType.SLAVE)
public List<SysUser> selectUserList(SysUser user)
{
return userMapper.selectUserList(user);
}
手动切换数据源
在需要切换数据源的方法中使用DynamicDataSourceContextHolder类实现手动切换
public List<SysUser> selectUserList(SysUser user)
{
DynamicDataSourceContextHolder.setDataSourceType(DataSourceType.SLAVE.name());
List<SysUser> userList = userMapper.selectUserList(user);
DynamicDataSourceContextHolder.clearDataSourceType();
return userList;
}
从库需要另外配置,如果不需要不用配置,也可以配置多个数据源
代码生成
在配置文件中可以配置代码生成默认配置
# 代码生成
gen:
# 开发者姓名,生成到类注释上
author: ruoyi
# 默认生成包路径 system 需改成自己的模块名称 如 system monitor tool
packageName: com.ruoyi.system
# 自动去除表前缀,默认是false
autoRemovePre: false
# 表前缀(生成类名不会包含表前缀,多个用逗号分隔)
tablePrefix: sys_
使用(直接在网页操作)
1.登录系统,系统工具,代码生成,导入表
2.代码生成列表中找到需要的表
3.点击生成会得到一个zip,执行sql文件,按照包内目录结构复制到项目中
定时任务
在指定的时间执行
系统接口(接口文档生成)
通过Swagger,在代码上添加注释,自动形成接口文档
作用范围 API 使用位置
协议集描述 @Api 用于controller类上
对象属性 @ApiModelProperty 用在出入参数对象的字段上
协议描述 @ApiOperation 用在controller的方法上
Response集 @ApiResponses 用在controller的方法上
Response @ApiResponse 用在 @ApiResponses里边
非对象参数集 @ApiImplicitParams 用在controller的方法上
非对象参数描述@ApiImplicitParam 用在@ApiImplicitParams的方法里边
描述返回对象的意义 @ApiModel 用在返回对象类上
防重复提交
在接口方法上添加@RepeatSubmit注解
参数 类型 默认值 描述
interval int 5000 间隔时间(ms),小于此时间视为重复提交
message String 不允许重复提交,请稍后再试 提示消息
interval可以自定义值
@RepeatSubmit(interval = 1000, message = "请求过于频繁")
public AjaxResult addSave(...)
{
return success(...);
}
国际化支持(i18n)
1.修改I18nConfig设置默认语言,如默认中文
slr.setDefaultLocale(Locale.SIMPLIFIED_CHINESE);
2.修改yml文件中basename国际化文件
spring:
# 资源信息
messages:
# 国际化资源文件路径
basename: static/i18n/messages
3.i18n目录文件下定义资源文件,每个语言分为一个个properties文件
例如
美式英语 messages_en_US.properties
user.login.username=User name
user.login.password=Password
user.login.code=Security code
user.login.remember=Remember me
user.login.submit=Sign In
中文简体 messages_zh_CN.properties
user.login.username=用户名
user.login.password=密码
user.login.code=验证码
user.login.remember=记住我
user.login.submit=登录
代码中使用MessageUtils获取国际化
MessageUtils.message("user.login.username")
MessageUtils.message("user.login.password")
MessageUtils.message("user.login.code")
MessageUtils.message("user.login.remember")
MessageUtils.message("user.login.submit")
新建子模块
1.新建一个子模块
2.在子模块下新建Pom文件及jave,resources目录
3.根目录添加子模块依赖
<dependency>
<groupId>com.ruoyi</groupId>
<artifactId>ruoyi-test</artifactId>
<version>${ruoyi.version}</version>
</dependency>
4.根目录添加子模块业务模块
<module>ruoyi-test</module>
5.ruoyi-admin中pom文件添加子模块依赖
<!-- 测试模块-->
<dependency>
<groupId>com.ruoyi</groupId>
<artifactId>ruoyi-test</artifactId>
</dependency>
6.测试子模块
SpringSecurity
SpringSecurity主要从两个方面解决安全性问题
1.web请求级别:使用Servlet规范中的过滤器(Filter)保护Web请求并限制URL级别的访问
2.方法调用级别:使用SpringAOP保护方法的调用,确保具有适当权限的用户才能访问安全保护的方法。
注解解析
@EnableWebSecurity:启动Web安全功能,本身并没有什么用,SpringSecurity的配置类需要实现WebSecurityConfigurer或继承WebSecurityConfigurerAdapter类
@EnableWebMvcSecurity:spring4.0已弃用
WebSecurityConfigurerAdapter类:可以通过重载该类的三个configure方法制定Web安全的细解
1.configure(WebSecurity):通过重载该方法,配置SpringSecurity的Filter链
2.configure(HttpSecurity):通过重载该方法,可配置如何通过拦截器保护请求
3.configure(AuthenticationManagerBuilder):通过重载该方法,可配置user-detail服务。
保护路径的配置方法
access(String) 给定的SpEL(Spring Expression Language)表达式计算为true,允许访问
anonymous() 允许匿名用户访问
authenticated() 允许认证过的用户访问
denyAll() 无条件拒绝所有访问
fullyAuthenticated() 如果用户完整认证(不是通过Remember me认证的)就允许访问
hasAnyAuthority(String..) 如果用户具备给定权限中的一个,就允许访问
hasAnyRole(String...) 如果用户具备给定角色中的某一个,就允许访问
hasAuthority(String) 如果用户具备给定权限,就允许访问
haslpAddress(String) 如果请求来自给定ip,就允许访问
hasRole(String) 如果用户具备给定角色,就允许访问
not() 对其他访问方法的结果求反
permilAll() 无条件允许访问
rememberMe() 如果用户是通过Remember-me功能认证的,就允许访问你
支持的SpEL表达式
authentication 用户认证对象
denyAll 结果始终为false
hasAnyRole(list of roles) 如果用户被授予指定任意权限,为true
hasRole(role) 如果用户被授予指定权限,为true
hasIpAddress(IP Adress) 用户地址
isAnonymous() 是否为匿名用户
isAuthenticated() 不是匿名用户
isFullyAuthenticated 不是匿名也不是remember me认证
isRememberMe() remember me认证
permitAll 始终为true
principal 用户主要信息对象
用户信息存储的三种方法
1.使用基于内存的用户存储:通过inMemoryAuthentication()方法,可以启用配置并任意填充基于内存的用户存储,并且可以调用withUser()方法为内存用户存储添加新的用户,这个方法的参数是username.withUser()方法返回的是UserDetailsManagerConfigurer.UserDetailsBuilder,这个对象提供了多个进一步配置用户的方法,包括设置用户密码的password()方法及为指定用户授予一个或多个角色权限的roles()方法。roles()方法是authorities()方法的简写形式。roles()方法所给定的值都会添加一个ROLE_前缀,并将其作为权限授予给用户。因此上述代码用户具有的权限为:ROLE_USER,ROLE_ADMIN.而借助passwordEncoder()方法来指定一个密码转码器(encoder),可以对用户密码进行加密存储
2.基于数据库表的认证:用户数据通常会存储在关系型数据库,并通过JDBC进行访问。为了配置SpringSecurity使用以JDBC为支撑的用户存储,可以使用jdbcAuthentication()方法,并配置他的DataSource,这样就能访问关系型数据库了。
3.基于LDAP进行认证:为了让SpringSecurity使用基于LDAP的认证,可以使用ldapAuthentication()方法。
SpringSecurity方法调用级别的安全性Demo
SpringSecurity提供了三种不同的安全注解:
1.SpringSecurity自带的@Secured注解
2.JSR-250的@RolesAllowed注解
3.表达式驱动的注解
@PreAuthorize 方法调用前,基于表达式的计算结果来限制对方法的访问
@PostAuthorize 允许方法调用,但如果表达式计算结果为false,抛出一个安全性异常
@PreFilter 允许方法调用,但必须按照表达式来过滤方法的结果
@PostFilter 允许方法调用,但必须在进入方法之前过滤输入值
基于注解的方法安全性、
在spring中如果要启用基于注解的方法安全性,关键在于要在配置类(@Configuration)上使用@EnableGlobalMethodSecurity注解
@EnableGlobalMethodSecurity(prePostEnabled = true, securedEnabled = true)
securedEnabled=ture 表示spring会创建一个切点,并将带有@Secured注解的方法放入切面中。prePostEnabled=true表示启用表达式驱动的注解,还有jsr250Enable=true表示启用@RoledAllowed
jwt(token)
JSON WEB TOKENS
流行,安全,稳定,易用,支持JSON
跨域身份验证
1.用户向服务器发送用户名和密码
2.验证服务器后,相关数据保存在当前会话
3.服务器向用户返回session_id,session信息写入用户Cookie
4.用户每个后续请求都通过Cookie中取出session_id传给服务器
5.服务器收到session_id并对比之前保存的数据,确认用户身份
问题:没有分布式,不支持横向扩展。如果单个服务器,该模式很好用。但如果是服务器集群或面向服务的跨域体系结构,需要一个统一的session数据库来保存会话数据实现共享,这样负载均衡下的每个服务器才可以正确验证用户身份。
例如,站点A和B提供同一公司的相关服务,现在要求登录A就会自动登录B,如何实现?
一种方法是把session数据持久化,写入数据库或文件持久层,收到请求后直接从持久层请求数据,架构清晰,但架构修改困难。由于依赖持久层的数据库,如果持久层挂了,整个认证系统都会挂掉。
jwt就是用来解决这种问题。客户端保存数据,服务器不保存会话数据,每个请求都被发送回服务器
jwt是在服务器身份验证之后将生成一个json对象发送回用户
如
{
“UserName”:"ayane"
"Role":"Admin"
"Expire":"2022-4-1 11:11:11"
}
之后当用户与服务器通信时,客户在请求中返回json对象,服务器仅依赖于这个json对象标识用户。为了防止用户篡改数据,服务器会在生成对象时添加签名,服务器不会保存任何会话数据,变为无状态,使其容易扩展
jwt数据结构
该对象是一个很长的字符串,字符之间用“.”分成三个子字符串,本质就是一个长串。
这个长串由jwt头,有效荷载,签名组成。
jwt头
这是一个描述JWT元数据的json对象,通常如下
{
“alg”: "HS256"
"typ" :“JWT”
}
alg属性表示签名使用的算法,默认是HS256,typ属性表示令牌的类型,JWT令牌统一写为JWT
最后,使用Base64 URL算法将上述json对象转换为字符串保存
有效荷载
是JWT的主体内容部分,是一个JSON对象,包含需要传递的数据,JWT默认指定七个默认字段供选择
iss:发行人
exp:到期时间
sub:主题
aud:用户
nbf:在此之前不可用
iat:发布时间
jti:JWT ID用于标识该JWT
除了这几个,还可以自定义私有字段
{
"sub": "1234567890",
"name": "zuocanglingyin",
"admin": true
}
注意:默认情况下JWT是未加密的,任何人都可以解读其内容,所以不要构建隐私信息字段,存放保密信息,防止信息泄露
它也会用Base64URL算法转换成字符串
签名哈希
这是对上面两部分数据的签名,通过指定算法生成哈希确保数据不会被篡改
首先指定一个密码secret,仅仅保存在服务器,不向用户公开,然后使用标头中指定的签名算法,根据以下公式生成签名
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload),secret)
计算出签名后,这三个部分组合成一个字符串,用.分隔,构成整个jwt对象
Base64URL算法
如前所述,JWT头和有效载荷序列化的算法都用到了Base64URL。该算法和常见Base64算法类似,稍有差别。
作为令牌的JWT可以放在URL中(例如api.example/?token=xxx)。 Base64中用的三个字符是"+","/"和"=",由于在URL中有特殊含义,因此Base64URL中对他们做了替换:"="去掉,"+"用"-"替换,"/"用"_"替换,这就是Base64URL算法。
JWT用法
客户端接受服务器返回的JWT,将其存储在cookie或localstorage中。客户端将在与服务器交互中都会带JWT。如果存在cookie,就可以自动发送,但不跨域。所以一般放入http请求的Header Authorization字段中。
Authorization:Bearer
跨域时,也可以将JWT被放置于POST请求的数据主体中。
JWT问题和趋势
1.JWT默认不加密,但可以加密。生成原始令牌后可以改令牌对其再次加密
2.JWT未加密方法时,一些私密数据无法通过JWT传输
3.JWT不仅可用于认证,也可以用于信息交换。善用JWT有助于减少服务器请求数据库次数
4.JWT最大缺点是服务器不保存会话状态,所以使用期间不可能取消令牌或更改令牌的权限,JWT一旦签发,在有效期内一直有效
5.JWT本身包含认证信息,一旦信息泄露,任何人都能获得令牌的所有权限,为了减少盗用,JWT有效期不宜太长,对于重要操作,用户使用时应该每次都进行身份验证
6.为了减少盗用和窃取,JWT不建议用HTTP协议传输代码,使用加密的HTTPS协议传输
RabbitMQ
前景
一个商品的价格修改了,他是在数据库中修改的,商品详情都有页面静态化处理,不会跟着数据库商品更新而变化,于是在数据库改了之后,前台页面上的价格还是旧的。
解决方法
1.每次修改数据库中商品信息时,同时修改索引库数据并更新静态页面
2.搜索服务和商品页面静态化服务对外提供操作接口,后台改完后重新调用接口
这两个方案都有严重的代码耦合,违背了微服务的独立原则。有一种解决方法:消息队列。
商品服务对商品增删改查后,不去操作索引库和静态页面,只向MQ发送一条消息(如包含商品id的消息),不去关心消息接受对象。搜索服务和静态页面服务监听MQ接收到消息,分别取处理索引库和静态页面(根据商品id操作)
什么是消息队列
MQ:Message Queue。它是消息在传输过程中保存消息的容器。典型的生产者,消费者模型。生产者不断向消息队列中生产消息,消费者不断从队列中获取消息。消息的产生和消费是异步的,并且只关心消息的发送和接受,没有业务逻辑侵入,实现了生产者和消费者的解耦。
应用场景
1.任务异步处理
高并发环境,来不及同步处理,请求往往会发生堵塞。比如大量的insert和update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。使用消息队列,可以异步处理请求,缓解系统压力,不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理,减少了应用程序的响应时间。
2.MQ相当于一个中介,生产方通过MQ与消费方交互,将应用程序进行解耦。
AMQP和JMS
MQ是消息通信的模型,并发具体实现。实现MQ的两种主流方式:AMQP,JMS区别和联系
1.JMS定义了统一的接口来对消息操作进行统一,AMQP是通过规定协议来统一数据交互的格式。
2.JMS限定使用JAVA,AMQP只是协议,不规定实现方式,因此是跨语言的。
3.JMS规定了两种消息模型,AMQP消息模型更丰富。
常见MQ
ActiveMQ:基于JMS
RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
RocketMQ:基于JMS,阿里产品,交由Apache基金会
Kafka:分布式消息系统,高吞吐量
安装erlang 和rabbitMQ
RabbitMQ组成部分
Broker:消息队列服务进程,此进程包括Exchange和Queue
Exchange:消息队列交换机,按一定规则将消息路由转发到某个队列,对消息进行过滤
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的
Producer:消息生产者,即生产方客户端,生产方客户端将消息发送
Consumer:消息消费者,即消费方客户端,接受MQ转发的消息
生产者发送消息流程:
1.生产者和Broker建立TCP连接
2.生产者和Broker建立通道
3.生产者通过通道消息发送给Broker,由Exchange将消息进行转发
4.Exchange将消息转发到指定的Queue
消费者接受消息流程:
1.消费者和Broker建立TCP连接
2.消费者和Broker建立通道
3.消费者监听指定的Queue
4.当有消息到达Queue时Broker默认将消息推送给消费者
5.消费者接收到消息
6.ack回复
六种消息模型
1.基本消息模型
p——>队列——>c
P:生产者,要发送消息的程序
C:消费者,消息的接收者,会一直等待消息到来
队列:消息队列,可以缓存消息,生产者向其中投递消息,消费者从其中取出消息。
消费者获取了消息,但程序没有停止,一直在监听队列中是否有新的消息,一旦有新消息进入队列,就会立即打印
消息确认机制(ACK)
消息一旦被消费者接受,队列中的消息就会被删除。
那么RabbitMQ怎么知道消息被接受了?如果消费者领取消息后还未操作就挂掉了,或抛出了异常,消息消费失败,但RabbitMQ无从得知,这样消息就丢失了。
因此,RabbitMQ有一个ACK机制,当消费者获取消息后,会向RabbitMQ发送回执ACK,告诉消息已被接受,回执ACK分两种情况:
1.自动ACK:消息一旦被接受,消费者自动发送ACK
2.手动ACK:消息接收后,不发送ACK,需要手动调用
这两种哪个好需要看消息的重要性,如果消息不太重要,丢失也没有影响,那么自动ACK很方便,如果消息非常重要,不能丢失,那最好在消费完成后手动ACK,否则接受消息就自动ACK,RabbitMQ就会把消息从队列中删除,如果此时消费者宕机,那么消息就丢失了
channel.basicConsume(QUEUE_NAME, true, consumer); 自动是true,手动要设为falser
2.work消息模型
工作队列或竞争消费者模型
p——>队列——>两个不同的消费者C1,C2
与前一个相比,多了一个消费端,两个消费者共同消费同一个队列中的消息,但消息只能被一个消费者获取。
这个模型在WEB应用中很有用,可以处理短的HTTP请求窗口中无法处理复杂的任务。
p:生产者,任务的发布者
C1:消费者1:领取并且完成任务,假设完成速度较慢
C2:消费者2:领取并且完成任务,假设完成速度较快
模拟发现,两个消费者各自消费了不同25条消息,实现了任务的分发
能者多劳
消费者1比2效率低,一次任务耗时长,然而两人最终消费的消息数量是一样的,消费者2大量时间空闲,消费者1一直在干活,现在任务平均分配,正确的做法是消费越快的,消费越多
如何实现
通过BasicQos方法设置prefetchCount=1.这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理1个Message,在接收到该Consumer的ack前,它不会将新的Message分发给它,相反,它会将其分派给不是仍然忙碌的下一个Consumer。
注意,prefetchCount在手动ACK的情况下才生效,自动ACK不生效。
模拟后,消费者2明显消费了更多条消息
订阅模型分类
1.一个生产者多个消费者
2.每个消费者都有一个自己的队列
3.生产者没有将消息直接发给队列,而是发给exchange(交换机,转发器)
4.每个队列都需要绑定到交换机上
5.生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者消费
例如:注册帐号,同时发邮件和短信
Exchange交换机一方面接受生产者发送的消息,另一方面知道如何处理消息,例如递交给某个特别队列,递交给所有队列,或是将消息丢弃,如何操作取决于Exchange的类型。
Exchange分为以下几种
Fanout:广播,将消息交给所有绑定到交换机的队列
Direct:定向,把消息交给符合指定routing key的队列
Topic:通配符,把消息交给符合routing pattern的队列
Header:取消routingkey,使用header中的kv键值对匹配队列
交换机只负责转发消息,不具备存储消息的能力,如果没有任何队列与Exchange绑定,或没有符合路由规则的队列,消息会丢失。
3.publish/subscribe(交换机类型:Fanout广播)
P——>X——>多个队列——>绑定各自队列的消费者
不同之处:生产者声明交换机,不再声明队列,消费者声明队列,绑定交换机。发送消息给交换机,不在发送给队列
思考:这个跟工作队列有什么区别
1.工作队列不用定义交换机,这个需要定义
2.这个的生产者是向交换机发送消息,工作队列是向队列发送消息
3.这个需要设置队列与交换机的绑定(消费者类设定)
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
相同点:二者实现的发布/订阅效果是一样的,多个消费者监听同一个队列不会重复消费
实际工作建议用p/s模式,p/s模式比工作队列模式更强大,并且可以指定专用的交换机
4.Routing 路由模型(交换机:direct)
p——>X——>routingkey(error,info,warning)——>多个队列——>各自的消费者
P:生产者,向交换机发送消息,发送消息时会指定一个routing key
X:交换机,接受生产者发送的消息,然后把消息递交给与routing key完全匹配的队列
消费者:其所在队列指定了需要的routing key类型的消息
生产者指定一个routing key
channel.basicPublish(EXCHANGE_NAME, "sms", null, message.getBytes());
只有与之匹配的消费者才能接受到生产者发来的消息
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "sms");
5.Topics通配符模式(交换机类型:topics)
每个消费者监听自己的队列,并设置带通配符(*,#)的routingkey,生产者将消息发给broker,由交换机根据routingkey转发消息到指定队列
这里的routingkey一般都是由一个或多个单词组成,多个单词中间用.分割,如orange.animal,橙色的动物
通配符规则:
#:匹配一个或多个词
*:只匹配1个词
audit.#:能够匹配audit.irs.corporate 或者 audit.irs
audit.*:只能匹配audit.irs
6.RPC
Callback queue回调队列。客户端向服务器发送请求,服务器端处理请求后,将处理结果保存在一个存储体,客户端为了获取处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识,客户端可能会发送多个请求到服务器。服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求向对应。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有的correlation_id,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
流程
1.客户端启动时,会创建一个匿名独享的回调队列
2.在RPC请求中,客户端发送带有两个属性的消息:一个是设置回调队列的reply_to属性,一个是设置唯一值的correlation_id属性
3.将请求发送到一个rpc_queue队列
4.服务器等待请求发送道这个队列中,当请求出现时,它执行他的工作并将带有执行结果的消息发送给reply_to指定的队列
5.客户端等待回调队列里的数据。当有消息出现时,会检查correlation_id属性,如果匹配,返回给应用
避免消息堆积
1.采用workqueue,多个消费者监听同一队列
2.接受消息后,通过线程池异步消费
避免消息丢失
消费者ACK机制,防止消费者丢失消息
如果消费之前MQ宕机了,消息没了怎么办?
将消息持久化,前提是队列交换机都持久化
Docker
关键词:软件带环境安装
Docker镜像(images)将应用程序所需要的系统环境由下而上打包,达到应用程序跨平台间的无缝接轨运作
Docker基于Go语言开发的云开源项目,通过对应用组件的封装,分发,部署,运行等生命周期的管理,使用户的APP及其运行环境做到一次封装,到处运行。
虚拟机也是带环境安装的一种解决方案,它可以在一种操作系统中运行另一种操作系统,但它资源占用多,冗余步骤多,启动慢,所以linux发展了另一种虚拟化技术,linux容器。
linux容器不是模拟一个完整的操作系统,而是对进程进行隔离,有了容器,可以将软件运行所需的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源和设置,系统因此而变得高效轻量并保证部署在任何环境中的软件都能始终如一的运行。
Docker和传统虚拟化方式的不同之处
1.传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整的操作系统,在该系统上再运行所需应用进程
2.容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,也没有进行硬件虚拟,因此容器要比传统虚拟机更为轻便
3.每个容器之间相互隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。
更快速的应用交付和部署
传统的应用开发完后,需要提供一堆安装程序和配置说明文档,安装部署后根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像内已经安装好,大大节省部署配置和测试验证时间
更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块积木,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至妙级。
更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发,测试环境的应用高度一致,容器会将应用程序相关的环境与状态完全封装,不会因为底层基础架构和操作系统不一致给应用带来影响,产生新的BUG,当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复
更高效的计算资源利用
Docker是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的Hypervisor(管理程序)支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
Docker的基本组成
镜像(image)
Docker镜像就是一个只读的模板。镜像可以用来创建Docker容器,一个镜像可以创建很多容器。就好似Java中的类和对象,类是镜像,容器是对象。
容器(container)
Docker利用容器独立运行一个或一组应用。容器是用镜像创建的运行实例、
容器可以被启动,开始,停止,删除,每个容器都是互相隔离的,保证安全的平台,可以把容器看作是一个简易版的Linux环境和运行在其中的应用程序。容器的定义和镜像几乎一模一样,也是一堆层的统一视角,唯一区别在于容器的最上面那一层是可读可写的
仓库(repository)
仓库是集中存放镜像文件的场所。
仓库和仓库注册服务器是有去别的。仓库注册服务器上往往存放着多个仓库,每个仓库又包含多个镜像,每个镜像有不同的标签tag,仓库分为空开仓库和私有仓库两种形式,最大的公开仓库是DockerHUb,存放了数量庞大的镜像供用户下载。阿里云,网易云
小结
1.Docker本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包好形成一个可交付的运行环境,这个打包好的运行环境就似乎image镜像文件。只有通过这个镜像文件才能生成Docker容器。image文件可以看作是容器的模板。Docker根据image文件生成容器的实例,同一个image文件可以生成多个同时运行的容器实例。
2.image文件生成的容器实例本身也是一个文件,称为镜像文件
3.一个容器运行一种服务,当我们需要的时候,就可以通过Docker客户端创建一个对应的运行实例,也就是容器
4.仓库就是放了一堆镜像的地方,可以把镜像发布到仓库,需要的时候从仓库拉下来就可以
Docker是怎么工作的
Docker是一个Client-Server(C/S)结构的系统,Docker守护进程运行在主机上,然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。容器是一个运行时环境,就是集装箱
为什么Docker比VM快
1.docker抽象层比虚拟机更少。由于docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源,因此在CPU,内存利用率上会更战优势
2.docker利用的是宿主机的内核,而不需要Guest OS。因此,当新建一个容器时,docker不需要和虚拟机一样重新加载一个操作系统内核,从而避免引寻,加载操作系统内核这些比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,新建过程都是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了这个过程,因此新建一个docker容器只需要几秒钟
Docker常用命令
帮助命令
docker version 版本信息
docker info 系统信息,包括镜像和容器数量
docker --help 帮助
镜像命令
docker images
列出本地主机上的镜像。
REPOSITORY 镜像的仓库源
TAG 镜像的标签
IMAGE ID 镜像的ID
CREATED 镜像的创建时间
SIZE 镜像的大小
同一个仓库源可以有多个TAG,代表这个仓库源的不同版本,我们使用REPOSITORY:TAG定义不同的镜像,如果不定义镜像的标签版本,docker将默认使用lastest镜像
-a:列出本地所有镜像
-q:只显示镜像id
--digests:显示镜像的摘要信息
docker search
搜索镜像
例:docker serch mysql
可选项
--filter=stars=50:列出收藏数不小于指定值的镜像
docker pull
下载镜像
例:docker pull mysql
可以指定版本现在 docker pull mysql:5.7
docker rmi
删除镜像
docker rmi -f 镜像id 删除单个
docker rmi -f 镜像名:tag 镜像名:tag 删除多个
docker rmi -f $(docer images -qa) 删除全部
容器命令
有镜像才能创建容器
Thymeleaf
thymeleaf是什么
这是一个模板引擎,因为支持html原型,在有网和无网环境都可运行,在html标签增加额外属性来达到模板+数据的展示方法。通常结合springboot使用
在springboot中的配置
1.添加pom文件依赖
2.创建模板文件夹。springboot自动为thymeleaf注册了一个视图解析器,如果没有在Yml文件中配置,它去找的视图文件默认在resources配置文件夹下的templates文件夹,后缀html。
Controller层返回页面展示
return "admin/index" 返回到admin文件夹下的index.html
return "index" 返回到templates下的index.html
return "redirect:/admin" 重定向到某个请求,即执行一次/admin请求
return "index::blogList" 返回到index.html,但只更新blogList片段,通常就是ajax请求
在html中的基本使用
1.引入名称空间
<html lang="en" xmlns:th="http://www.thymeleaf"
2.表达式的使用
在html中只需在源标签名前加 th:即可,如th:src,th:href,th:text等
${ },变量表达式,它可以获取到controller层存入的Model的值
controller层:
model.addAttribute("name","ayane");
User user = new User("ayane",29);
model.addAttribute("user",user);
html页面:
<span th:text="${name}"></span>获得存入name的值 ayane
<span th:text="${user.age}"></span>获得特定属性age 29
当有数据传递过来,动态数据会替换成静态数据
*{ },选择变量表达式,可以省略对象名直接获取属性值
<div th:object="${user}">
<p th:text="*{name}"></p>
<p th:text="*{age}"></p>
</div>
#{ },Message表达式,主要从国际化配置文件中取值
3.URL的使用
绝对网址,绝对URL用于创建到其他服务器的链接,需要指定协议名称http或https
<a th:href="@{https://www.baidu}">百度</a>
上下文相关URL,即与项目相关联的的URL,假设war包为app.war,且没有在tomcat的server.xml配置项目的路径(Context),则在tomcat启动后,就会在webapps文件下产生一个app文件夹,此时app就是上下文路径(context)
页面这样写
<a th:href="@{/blog/search}">跳转</a>
thymeleaf解析后是这个格式
<a th:href="/app/blog/search">跳转</a>
服务器相关URL。与上下文路径相似,主要用于一个tomcat下运行有多个项目的情况。比如当前项目为app,如果tomcat还运行着一个otherApp,我们可以通过该方法访问otherApp的请求路径
页面这样想
<a th:href="@{~/otherApp/blog/search}">跳转</a>
thymeleaf解析后
<a th:href="/otherApp/blog/search">跳转</a>
页面带参数传递到后端
页面
<a th:href="@{/blog/search(id=3,blogName='Java')}">跳转</a>
解析后
<a th:href="/blog/search?id=3&blogName=Java">跳转</a>
restful风格
<a th:href="/blog/{id}/search(id=3&blogName=Java)">跳转</a>
解析后
<a th:href="/blog/3/search?blogName=Java">跳转</a>
4.字面值
有时候需要在指令中填入基本类型如字符串,数值,布尔值等,不希望thymeleaf解析
字符串字面值
页面
<span th:text="'Thymeleaf' + 3">templates</span>
解析后
<span>Thymeleaf3</span>
数字字面值
页面
<span th:text="'1+3">templates</span>
解析后
<span>4</span>
布尔字面值
true 和 false
5.拼接
传统拼接需要用''来进行普通字符串和表达式的拼接,thymeleaf中进行了简化,只需将拼接的内容块用||包裹
<span th:text="|欢迎您,${user.name}|"></span>
6.运算符
因为html会将<>符号进行解析,所以不能直接使用,但如果在{ }内使用是不需要转换的
> gt greater than,大于
< lt less than,小于
>= ge greater equal,大于等于
<= le less equal,小于等于
三元运算符
<span th:text="${false} ? '男' :'女' ">性别</span>
空值判断
如果user.name为空,则显示空值显示这四个字
<span th:text="${user.name} ?: '空值显示'"></span>
7.内联写法
[()],解析输出,会解析内容里的html标签
<span>[(${user.name})]</span>
[[]],原样输出,不会解析内容里的html标签
<span>[[${user.name}]]</span>
8.局部变量
可以将后端传来的数据赋值给一个局部变量,这个局部变量只能在标签内部用
<div th:with="user=${userList[0]}">
<span th:text="${user.name}">昵称</span>
<div>
9.判断
th:if,满足条件显示内容
<span th:if="${true}">显示</span>
<span th:if="${user.age==18}">年龄大于18岁显示</span>
th:unleff,与if相反,不满足时显示
<span th:unleff="${true}">不显示</span>
th:switch,与switch效果一致
<div th: switch = "${user.name}">
<span th:case="1">1</span>
<span th:case="2">2</span>
<span th:case="3">3</span>
</div>
10.迭代
th:each,迭代一个集合/数组,可以用它的内置对象stat获取更多信息
<tr th:each="user(,userStat):${userList}">
<td th:text="${user.name}"></td>
<td th:text="|当前迭代到第${stat.count}个了|"></td>
</tr>
这个userStat是自定义的一个迭代器,用于获取迭代状态,包含以下属性
1)index 属性:当前迭代索引,从0开始
2)count 属性:当前的迭代计数,从1开始
3)size 属性:迭代变量中元素的总量
4)current 属性:每次迭代的 iter 变量,即当前遍历到的元素
5)even/odd 布尔属性:当前的迭代是偶数还是奇数。
6)first 布尔属性:当前的迭代是否是第⼀个迭代
7)last 布尔属性:当前的迭代是否是最后⼀个迭代。
11、环境相关对象
1、${#ctx}:上下文对象,可用于获取其他内置对象
2、${#vars}:上下文变量。
3、${#locale}:上下文区域设置。
4、${#request}:HttpServletRequest对象。
5、${#response}:HttpServletResponse对象。
6、${#session}:HttpSession对象。
7、${#servletContext}:ServletContext对象。
12、全局对象功能
1、#strings:字符串工具类
2、#lists:List 工具类
3、#arrays:数组工具类
4、#sets:Set 工具类
5、#maps:常用Map方法。
6、#objects:一般对象类,通常用来判断非空
7、#bools:常用的布尔方法。
8、#execInfo:获取页面模板的处理信息。
9、#messages:在变量表达式中获取外部消息的方法,与使用#{…}语法获取的方法相同。
10、#uris:转义部分URL / URI的方法。
11、#conversions:用于执行已配置的转换服务的方法。
12、#dates:时间操作和时间格式化等。
13、#calendars:用于更复杂时间的格式化。
14、#numbers:格式化数字对象的方法。
15、#aggregates:在数组或集合上创建聚合的方法。
16、#ids:处理可能重复的id属性的方法。
13、class属性增加
使用th:classappend,可以增加class元素类名。通常用在如导航栏上,当导航栏上某个标签被选中,它会与其他没有被选中的有不同的样式。
<a class="item m-mobile-hide’ th:classappend='${n==1} ? ‘active’">首页</a>
<!-- 如果n==1成立,则解析如下 -->
<a class="item m-mobile-hide active’">首页</a>
在html页面中的布局使用
定义片段和引入片段功能用的很多,在一个项目的多个页面,大部分导航栏和底部是一样的,可以创建一个页面专门来定义重复使用的片段,在其他页面做引入。
1.定义片段
使用th:fragment定义通用片段-普通片段
<nav th:fragment="header">
<a href="#">首页</a>
<a href="#">分类</a>
</nav>
使用th:fragement定义通用片段-带参片段,根据“n”来判断样式
<nav th:fragment="header(n)">
<a class="item’ th:classappend='${n==1} ? ‘active’">首页</a>
<a class="item’ th:classappend='${n==2} ? ‘active’">分类</a>
</nav>
2.引入片段
将公共的标签插入到指定标签中-~{ }不可省略
<div th:insert="~{_fragment::header}">
//被引入的片段会插入到div标签内部
<div>
将公共的标签替换指定的标签-可以省略~{ }
推荐该引用方式,可以保证在没有网络(动态数据)的情况下其他页面也有内容可以显示
<div th:replace="~{_fragment::header}">
//被引入的片段会替换div标签的内容(含div)
<a href="#">链接</a>
<div>
将公共的标签包含到指定的标签-可以省略~{}
<div th:include="~{_fragment::header}">
//被引入的片段会被包含到div标签内部
//但是最外层的标签不会被包含进来,即只包含th:fragment所在标签内部的内容
</div>
上诉三种方法,可以用来引入使用id定义片段的 - 不推荐
<nav th:insert="~{_fragment::#header}">
<!-- 不推荐id定义片段和引入这种片段 -->
</nav>
引入带参片段
<nav th:replace="header(2)">
<a class="item’ th:classappend='${n==1} ? ‘active’">首页</a>
<a class="item’ th:classappend='${n==2} ? ‘active’">分类</a>
</nav>
3.th:fragment更新数据
有时在页面中需要使用Ajax异步请求数据,我们希望只更新某一块的数据,其他地方不变。
html页面:
<!-- 其他代码 -->
<div th:fragment="userInfo">
<span th:text="${user.name}">九月</span>
<span th:text="${user.age}">18</span>
</div>
<!-- 其他代码 -->
后台:
public String userInfo(Model model){
model.addAttribute(user,new User("柳成荫",22));
return "index :: userInfo";
}
4.块级标签th:block
thymeleaf处理这个标签时会删掉标签本身,不会显示标签但会保留其内容
常见用法-html部分
<!-- 控制几个标签是否一起显示/不显示 -->
<th:block th:if="...">
<div id="div1">我和div2一起</div>
<div id="div2">我和div1一起</div>
</th:block>
<!-- 循环统计标签 -->
<table>
<th:block th:each="...">
<tr>...</tr>
<tr>...</tr>
</th:block>
</table>
常见用法-JS部分
有时候js的引用也可能是其他页面共有的,想定义一个Js片段在其他页面引入,可以使用<div>把js片段包裹起来,然后将这个<div>定义成一个片段,但这个方法不好,所以用th:block。
<!-- JS公用部分 - 定义片段 -->
<th:block th:fragment="script">
<script src="../static/js/jquery-3.3.1.min.js" th:src="@{/js/jquery-3.3.1.min.js}"></script>
<script src="../static/js/semantic.min.js" th:src="@{/js/semantic.min.js}"></script>
</th:block>
引用
<th:block th:replace="_fragment::script">
<!-- 这样就解决了JS共用的问题了 -->
<script src="../static/js/jquery-3.3.1.min.js"></script>
</th:block>
这个标签不会影响静态页面。
MySQL存储过程
SQL语句需要先编译再执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果有)来调用执行它。
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数或封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看作是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
存储过程的优点:
1.增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
2.标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。数据库专业人员可以随时对存储过程进行修改,对应用程序源代码无影响。
3.较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对慢一些。
4.减少网络流量:针对同意数据库对象的操作(如查询,修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,减少网络流量并降低网络负载。
5.作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
MySQL5.0后开始支持存储过程,提高了数据库的处理速度,编程的灵活性。
MySQL存储过程的创建
语法
CREATE PROCEDURE 过程名 ([IN | OUT | INOUT ])参数名 数据类型[IN | OUT | INOUT ] 参数名 数据类型...]]) [特性.....] 过程体
例子:
DELIMITER //
CREATE PROCEDURE myproc (OUT s INT)
BEGIN
SELECT COUNT(*) INTO s FROM students;
END
//
DELIMITER;
分隔符
MySQL默认以";"为分隔符,如果没有声明分隔符,编译器会把存储过程当成SQL语句处理,因此编译过程会报错。所以要实现用"DELIMITER //"声明当前段分隔符,让编译器把两个
“//”之间的内容当作存储过程的代码,不会执行这些代码;
最后一句"DELIMITER;"的意思是把分隔符还原
参数
存储过程根据需要可能会有输入,输出,输入输出参数,如有多个参数用,分隔开.MySQL存储过程的参数必须用在存储过程的定义,共有三种参数类型:IN OUT INOUT
过程体
过程体的开始与结束使用BEGIN与END进行标识。
IN参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值。
DELIMITER //
CREATE PROCEDURE in_param(IN p_in int)
BEGIN
SELECT p_in;
SET p_in=2;
SELECT p_in;
END;
//
DELIMITER ;
#调用
SET @p_in = 1;
CALL in_param(@p_int);
SELECT @p_in;
执行结果:
1
2
1 存储过程中的set p_in =2 没有返回。
OUT该值可在存储过程内部被改变,并可返回
DELIMITER //
CREATE PROCEDURE out_param(OUT p_out int)
BEGIN
SELECT p_out;
SET p_out=2;
SELECT p_out;
END;
//
DELIMITER ;
#调用
SET @p_out = 1;
CALL out_param(@p_out);
SELECT @p_out;
执行结果:
null?好像是说这个参数传入存储过程后被清空了
2
2
INOUT调用时指定,并且可被改变和返回
DELIMITER //
CREATE PROCEDURE inout_param(INOUT p_inout int)
BEGIN
SELECT p_inout;
SET p_inout=2;
SELECT p_inout;
END;
//
DELIMITER ;
#调用
SET @p_inout=1;
CALL inout_param(@p_inout) ;
SELECT @p_inout;
执行结果
1
2
2
变量
语法:DECLARE 变量名1 [,变量名2....] 数据类型 [默认值];
数据类型为MySQL的数据类型,这不写了!
变量赋值
语法:SET 变量名 = 变量值
用户变量
用户变量一般以@开头
注意:滥用用户变量会导致程序难以理解及管理
#在MySQL客户端使用用户变量
SELECT 'HELLO WORLD' into @x;
SELECT @x;
SET @y='GoodBye';
SELECT @y;
SET @z=1+2+3;
SELECT @z;
结果:
HELLO WORLD
GoodBye
6
#在存储过程中使用用户变量
CREATE PROCEDURE GreetWorld() SELECT CONCAT (@greeting,'world');
SET @greeting = 'Hello';
CALL GreetWorld();
执行结果
Helloworld
#在存储过程间传递全局范围的用户变量
CREATE PROCEDURE p1() SET @last_proc='p1';
CREATE PROCEDURE p2() SELECT CONCAT('Last procedure was ',@last_proc);
CALL p1();
CALL p2();
执行结果
Last procedure was p1
注释
存储过程注释两种风格
1.双杠:--一般用于单行注释
2.C风格:一般用于多行注释
存储过程的调用
用call和过程名以及一个括号,括号内根据需要加入参数,如上述例子所示
存储过程的查询
#查询存储过程
SELECT name FROM mysql.proc WHERE db='数据库名';
SELECT routine_name FROM information_schema.routines WHERE routine_schema='数据库名';
SHOW PROCEDURE STATUS WHERE db='数据库名';
#查看存储过程详细信息
SHOW CREATE PROCEDURE 数据库.存储过程名;
存储过程的修改
ALTER PROCEDURE 更改用CREATE PROCEDURE建立的预先指定的存储过程,其不会影响存储过程或存储功能。
ALTER {PROCEDURE | FUNCTION } sp_name [characteristic ....]
characteristic:
{CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA |
SQL SECURITY {DEFINER | INVOKER} | COMMENT 'string'}
sp_name参数表示存储过程或函数的名字;
characteristic参数指定存储函数的特性
CONTAINS SQL表示子程序包含SQL语句,单不包含读或写数据的语句;
NO SQL表示子程序中不包含SQL语句
READS SQL DATA 表示子程序中包含读数据的语句
MODIFIES SQL DATA 表示子程序中包含写数据的语句
SQL SECURITY{DEFINER|INVOKER}指明谁有权限来执行,DEFINER表示只有定义者自己才能执行,INVOKER表示调用者可以执行
COMMENT 'string'是注释信息
例子:
#将读写权限改为MODIFIES SQL DATA ,并指明调用者可以执行
ALTER PROCEDURE num_from_employee
MODIFIES SQL DATA
SQL SECURITY INVOKER;
#将读写权限改为RAEDS SQL DATA,并加上注释信息“FIND NAME”
ALTER PROCEDURE name_from_employee
READS SQL DATA
COMMENT 'FIND NAME';
MySQL存储过程的删除
DROP PROCEDURE [过程1 [,过程2....]]
从MySQL的表格中删除一个或多个存储过程
MySQL存储过程的控制语句
变量作用域
内部变量在其作用域范围内享有更高的优先权,当执行到end时,内部变量消失,不再可见,在存储过程外再也找不到这个内部变量,但是可以通过Out参数或者将其值指派给会话变量来保存其值。
#变量作用域
DELIMITER //
CREATE PROCEDURE proc()
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT 'outer';
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT 'inner';
SELECT x1;
END;
SELECT x1;
END;
//
DELIMITER ;
#调用
CALL proc();
执行结果:
inner
outer
条件语句
IF-THEN-ELSE语句
#条件语句IF-THEN-ELSE
DROP PROCEDURE IF EXISTS proc3;
DELIMITER //
CREATE PROCEDURE proc3(IN parameter int)
BEGIN
DECLARE var int;
SET var=parameter+1;
IF var=0 THEN
INSERT INTO t VALUES (17);
END IF ;
IF parameter=0 THEN
UPDATE t SET s1=s1+1;
ELSE
UPDATE t SET s1=s1+2;
END IF ;
END ;
//
DELIMITER ;
CASE-WHEN-THEN-ELSE语句
#CASE-WHEN-THEN-ELSE语句
DELIMITER //
CREATE PROCEDURE proc4 (IN parameter INT)
BEGIN
DECLARE var INT;
SET var=parameter+1;
CASE var
WHEN 0 THEN
INSERT INTO t VALUES (17);
WHEN 1 THEN
INSERT INTO t VALUES (18);
ELSE
INSERT INTO t VALUES (19);
END CASE ;
END ;
//
DELIMITER ;
循环语句
WHILE-DO…END-WHILE
DELIMITER //
CREATE PROCEDURE proc5()
BEGIN
DECLARE var INT;
SET var=0;
WHILE var<6 DO
INSERT INTO t VALUES (var);
SET var=var+1;
END WHILE ;
END;
//
DELIMITER ;
REPEAT...END REPEAT
此语句的特点是执行操作后检查结果
DELIMITER //
CREATE PROCEDURE proc6 ()
BEGIN
DECLARE v INT;
SET v=0;
REPEAT
INSERT INTO t VALUES(v);
SET v=v+1;
UNTIL v>=5
END REPEAT;
END;
//
DELIMITER ;
LOOP...END LOOP
DELIMITER //
CREATE PROCEDURE proc7 ()
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
INSERT INTO t VALUES(v);
SET v=v+1;
IF v >=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END;
//
DELIMITER ;
LABLES标号
标号可以用在begin repeat while 或者loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。
ITERATE迭代
通过引用复合语句的标号,来从新开始复合语句
#ITERATE
DELIMITER //
CREATE PROCEDURE proc8()
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
IF v=3 THEN
SET v=v+1;
ITERATE LOOP_LABLE;
END IF;
INSERT INTO t VALUES(v);
SET v=v+1;
IF v>=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END;
//
DELIMITER ;
MySQL存储过程的基本函数
字符串类
CHARSET(str) //返回字串字符集
CONCAT (string2 [,... ]) //连接字串
INSTR (string ,substring ) //返回substring首次在string中出现的位置,不存在返回0
LCASE (string2 ) //转换成小写
LEFT (string2 ,length ) //从string2中的左边起取length个字符
LENGTH (string ) //string长度
LOAD_FILE (file_name ) //从文件读取内容
LOCATE (substring , string [,start_position ] ) 同INSTR,但可指定开始位置
LPAD (string2 ,length ,pad ) //重复用pad加在string开头,直到字串长度为length
LTRIM (string2 ) //去除前端空格
REPEAT (string2 ,count ) //重复count次
REPLACE (str ,search_str ,replace_str ) //在str中用replace_str替换search_str
RPAD (string2 ,length ,pad) //在str后用pad补充,直到长度为length
RTRIM (string2 ) //去除后端空格
STRCMP (string1 ,string2 ) //逐字符比较两字串大小,
SUBSTRING (str , position [,length ]) //从str的position开始,取length个字符,
注:mysql中处理字符串时,默认第一个字符下标为1,即参数position必须大于等于1
SELECT SUBSTRING('abcd',0,2);
结果:无
SELECT SUBSTRING('abcd',1,2);
结果:ab
TRIM([[BOTH|LEADING|TRAILING] [padding] FROM]string2) //去除指定位置的指定字符
UCASE (string2 ) //转换成大写
RIGHT(string2,length) //取string2最后length个字符
SPACE(count) //生成count个空格
数学类
ABS (number2 ) //绝对值
BIN (decimal_number ) //十进制转二进制
CEILING (number2 ) //向上取整
CONV(number2,from_base,to_base) //进制转换
FLOOR (number2 ) //向下取整
FORMAT (number,decimal_places ) //保留小数位数
HEX (DecimalNumber ) //转十六进制
注:HEX()中可传入字符串,则返回其ASC-11码,如HEX('DEF')返回4142143
也可以传入十进制整数,返回其十六进制编码,如HEX(25)返回19
LEAST (number , number2 [,..]) //求最小值
MOD (numerator ,denominator ) //求余
POWER (number ,power ) //求指数
RAND([seed]) //随机数
ROUND (number [,decimals ]) //四舍五入,decimals为小数位数] 注:返回类型并非均为整数,如:
SELECT ROUND(1.23);
1
SELECT ROUND(1.56);
2
#设定小数位数,返回浮点型数据
SELECT ROUND(1.567,2);
1.57
SIGN (number2 ) // 正数返回1,负数返回-1
日期时间类
ADDTIME (date2 ,time_interval ) //将time_interval加到date2
CONVERT_TZ (datetime2 ,fromTZ ,toTZ ) //转换时区
CURRENT_DATE ( ) //当前日期
CURRENT_TIME ( ) //当前时间
CURRENT_TIMESTAMP ( ) //当前时间戳
DATE (datetime ) //返回datetime的日期部分
DATE_ADD (date2 , INTERVAL d_value d_type ) //在date2中加上日期或时间
DATE_FORMAT (datetime ,FormatCodes ) //使用formatcodes格式显示datetime
DATE_SUB (date2 , INTERVAL d_value d_type ) //在date2上减去一个时间
DATEDIFF (date1 ,date2 ) //两个日期差
DAY (date ) //返回日期的天
DAYNAME (date ) //英文星期
DAYOFWEEK (date ) //星期(1-7) ,1为星期天
DAYOFYEAR (date ) //一年中的第几天
EXTRACT (interval_name FROM date ) //从date中提取日期的指定部分
MAKEDATE (year ,day ) //给出年及年中的第几天,生成日期串
MAKETIME (hour ,minute ,second ) //生成时间串
MONTHNAME (date ) //英文月份名
NOW ( ) //当前时间
SEC_TO_TIME (seconds ) //秒数转成时间
STR_TO_DATE (string ,format ) //字串转成时间,以format格式显示
TIMEDIFF (datetime1 ,datetime2 ) //两个时间差
TIME_TO_SEC (time ) //时间转秒数]
WEEK (date_time [,start_of_week ]) //第几周
YEAR (datetime ) //年份
DAYOFMONTH(datetime) //月的第几天
HOUR(datetime) //小时
LAST_DAY(date) //date的月的最后日期
MICROSECOND(datetime) //微秒
MONTH(datetime) //月
MINUTE(datetime) //分返回符号,正负或0
SQRT(number2) //开平方
更多推荐
2022Java面试题,非常全面
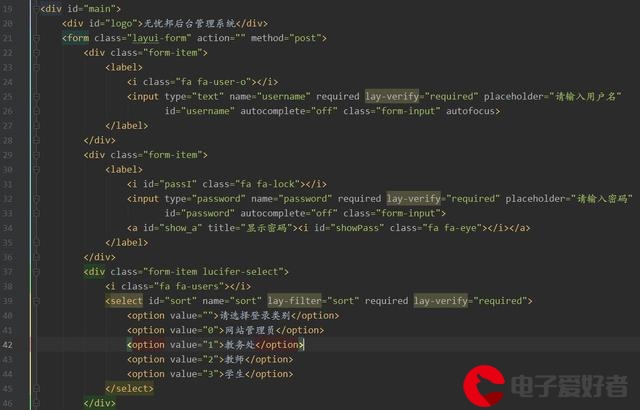








发布评论